
Author: Laura Teixeira da Rocha
Though important for many kinds of intelligence, rankings are often unreliable. Our proprietary technique for generating accurate rankings has addressed the issues with reliability, and our InfoRanks product gives a deep insight into a domain’s ranking and stability. In this article, we discuss the motivation behind InfoRanks and describe some of its features.
Fundamentally, top N rankings can be used as summaries of the vast amounts of data generated on the internet every day. The Domain Name System (DNS) is a fundamental ingredient of the internet, and the data it handles is used for many types of analyses. For example, at Infoblox we analyze DNS traffic to create rankings that we then use in our security products: as the foundation of our algorithm for creating allow-lists[1], as input for machine-learning algorithms, as enrichment of domains’ popularity in a customer’s network, and as a tool for prioritizing threats prevalent in a network.
Amazon’s Alexa Top 1 Million and other publicly available rankings of domains have been studied extensively[2][3]. The issues we have found in these studies have spurred us to create our patent-pending InfoRanks, which gives information about a ranking’s stability over time and circumvents the effect of noise on the ranking.
Conventional methods for calculating rankings rely on counting items and sorting them from highest frequency to lowest. Due to the variance in observations and the amount of activity on the internet, calculations that rely on simple counts of queries are affected by traffic noise caused by disruptions in the underlying network, changes in network configuration, seasonal marketing and news events, activity of malicious actors, and many other factors.
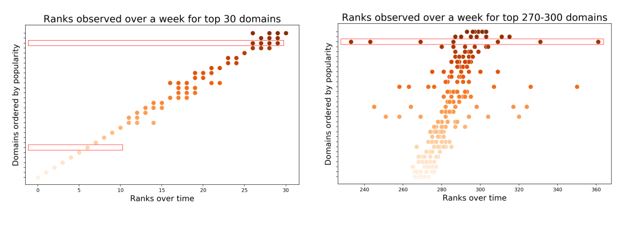
One unavoidable cause of a rank’s instability is the natural distribution of DNS queries in a network. Traditional methods that provide a single ranking do not convey the fact that a domain’s ranking loses stability as the domain’s popularity decreases. The plots below illustrate that the rankings of domains over several days, as measured by simply counting queries, have high variation towards the tail of the list. On the left, the rankings for top 30 domains vary by only a few positions or none; on the right, the rankings of less popular domains, even those very popular in the absolute sense (ranked from 270 to 300 in this example), can vary tremendously over time.
For the purpose of computing rankings, the Zipf statistical distribution can be used to model DNS queries. Due to Zipf’s law, which states that the frequency of events is inversely proportional to their rank, event counts are bound to collide towards the tail of the list. For calculating rankings, if we observe 100 domains the same number of times, what rankings do we assign to them? Traditional calculation assigns rankings in alphabetical order or randomly, even if the domains have the same counts and should have the same rankings. However, our method assigns the same ranking if a domain has appeared the same number of times, and this enables us to provide accurate information about the domain’s popularity.
InfoRanks mitigates inaccuracies in traditional count-sort methods and in methods used to provide a single ranking in an uncertain environment. The result provided by InfoRanks consists not only of a range of plausible rankings for a specific domain but also of the most likely single ranking in the time period during which observations are made. InfoRanks incorporates numerous days of activity to compute a ranking’s sample mean, uses bootstrap samplings, and applies confidence intervals (a statistical inference technique) to derive the ranking intervals and the single most-likely ranking. In the plot below, the ranking ranges are ordered by most-likely inferred ranking. The diagram shows that single rankings become more difficult to accurately determine as popularity decreases due to its variation across days.
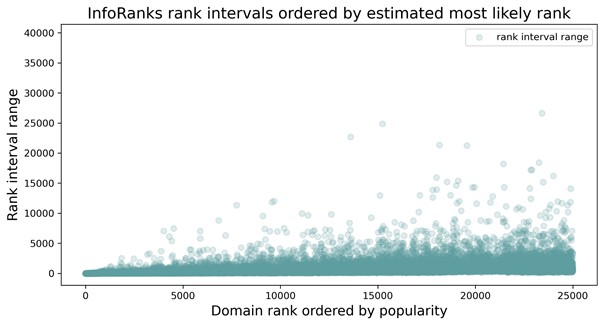
This approach allows domain rankings to “collide”: that is, to have the same ranking and still provide accurate information. With only a single ranking in hand, the user cannot see the relevant information about the data and cannot determine whether the information is consistent. By using intervals, however, the user can gain insight into a rank’s stability and select information according to a specific use case.
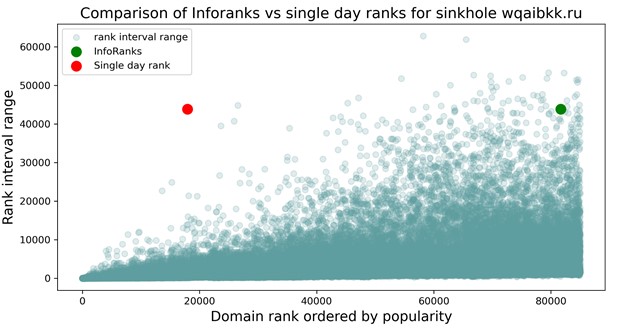
Variance in DNS traffic can also be caused by malicious actors. For example, phishing domains can generate strong, short-lived spikes in traffic and boost their rankings high enough that they look like legitimate domains. The plot below shows a sinkholed domain that is ranked high in popularity when only count-sort methods are used for determining the ranking (in red), even though the domain’s ranking varies by 630,000 units within a single week. The plot shows that our method assigns a less popular most-likely ranking to the example domain, showing InfoRanks robustness in the face of variability.
Using ranking intervals rather than a single ranking has many advantages and applications. Above all, ranking intervals provide accurate information and enable users to make better decisions according to the stability of data. This approach also opens possibilities for the creation of better analytics and for making products more secure.
- Renée Burton, Laura da Rocha, “Whitelists that Work: Creating Defensible Dynamic Whitelists with Statistical Learning,” 2019 APWG Symposium on Electronic Crime Research (eCrime), Pittsburgh, PA, USA, 2019, pp. 1-10, doi: 10.1109/eCrime47957.2019.9037505. https://blogs.infoblox.com/wp-content/uploads/infoblox-whitelists-that-work.pdf
- Victor Le Pochat, Tom Van Goethem, Samaneh Tajal-izadehkhoob, Maciej Korczynski, and Wouter Joosen. “Tranco: A Research-Oriented Top Sites Ranking Hard- ened Against Manipulation”. In: Proceedings of the 26th Annual Network and Distributed System Security Symposium. NDSS 2019. Feb. 2019. DOI: 10.14722/ndss.2019.23386. URL: https://tranco-list.eu.
- Quirin Scheitle, Oliver Hohlfeld, Julien Gamba, Jonas Jelten, Torsten Zimmermann, Stephen D. Strowes, and Narseo Vallina-Rodriguez. “A Long Way to the Top: Significance, Structure, and Stability of Internet Top Lists”. In: CoRR abs/1805.11506 (2018). arXiv: 1805. 11506. URL: http://arxiv.org/abs/1805.11506.