




Domain Name Security (DNS) security products protect both their customers and their customer’s users from a wide variety of malicious actors. In order to provide this protection, these products utilize blacklists composed of domain names and IP addresses that are considered harmful. Infoblox’s threat feeds are curated by our Cyber Intelligence team and are derived from both statistical and heuristic methods. Some threats are derived from a customer’s network dynamically, while others are taken from the global DNS perspective. Infoblox® faces the industry-wide challenge of protecting our customer’s networks from security threats while ensuring access to critical Internet resources. Similar to other companies in the security industry facing this challenge, Infoblox utilizes whitelists to reduce the potential of interfering with legitimate traffic from our users. Whitelists are essentially a list of domains or IP addresses that are considered benign, and thus should not be included in our threat feeds. Our customers can create private whitelists, but it is our goal to make these redundant. Rather, we have invested heavily in the research and development of machine learning-built whitelists and scoring systems to progressively automate more and more of this function. While this work is ongoing, we are excited to share our current algorithms and the supporting data science that led to their design. The patent-pending algorithm, which we call Smartlisting, was published as part of the Anti-Phishing Working Group eCrime conference of 2019 [1].
In theory, a whitelist contains known benign indicators that are important to users, and it serves to counter mistakes that might exist in a threat feed. In practice, whitelists are often manually crafted and ill-maintained, resulting in stale information which may ultimately prove to increase, rather than decrease, the risk of compromise to users. A common practice is to use a self-determined heuristic based on publicly available popularity lists for domains, such as the Alexa Top 1M domains [2]. This is then supplemented by domains that were previously found to be false positives. However, this approach to whitelisting is filled with uncertainty and poses the question: where should one threshold the whitelist? A list that is too small will fail to protect users from false positives, and a list that is too big will likely contain malicious domains.
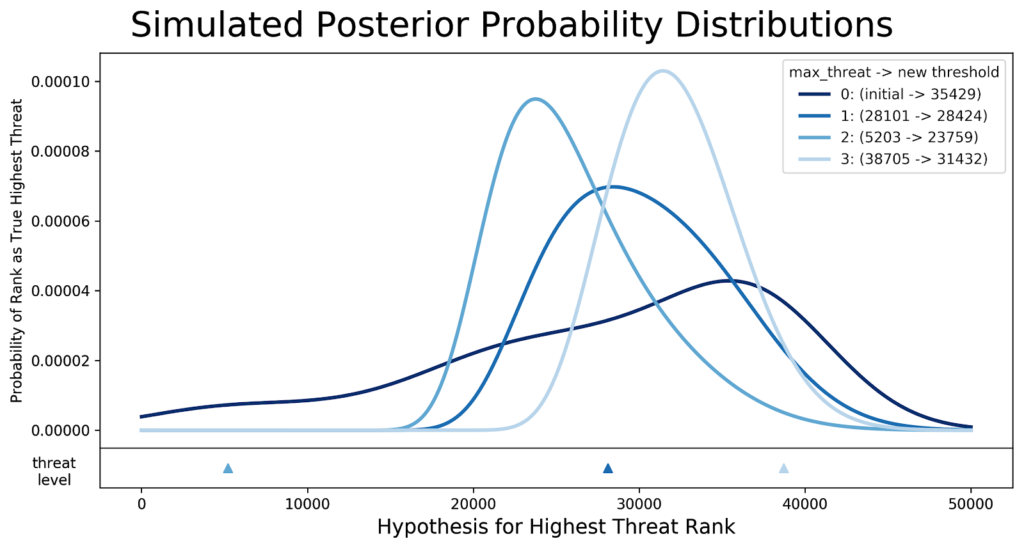
Instead of considering only the popularity of domains, we incorporate current threats into our algorithm, specifically the popularity of those threats. Through the use of Bayesian inference modeling, we are able to create a whitelist that continually adapts to the environment, resizing as the threat levels change. As a result, the whitelist is as small, and as large, as the risk to our customers will allow. The entire whitelist is recalculated regularly and our parameters automatically adjusted. The model essentially learns a threshold within the domain rankings, above which domains are put into the current whitelist. In the figure below, the whitelist threshold is seen to move accordingly as the threat levels change. In this example, while initially set at 35,429, we see that the threshold and the size of the whitelist change over time.
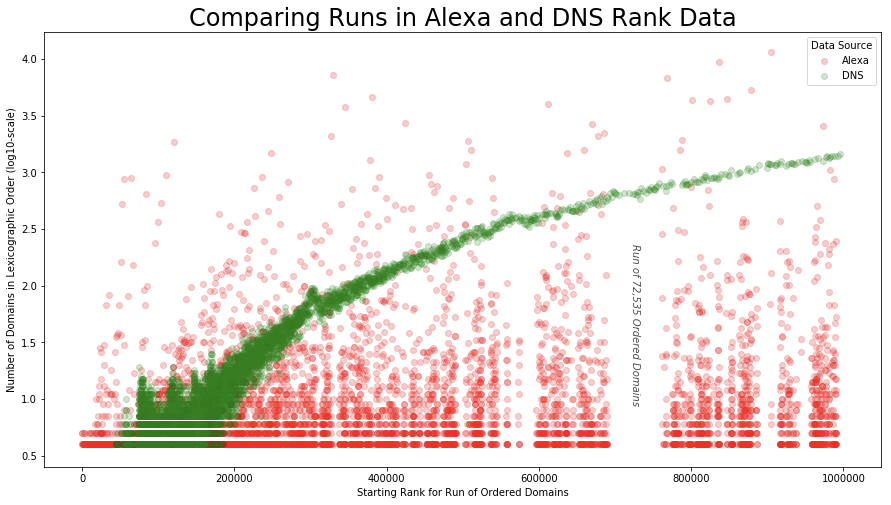
This algorithm only works with high quality popularity ranking and threat data. We rigorously researched the theory and application of rankings in DNS domain data, studying both internal data and several publicly available sources of domain rankings. Like others in the security industry [3] [4], we found integrity issues with the Alexa Top 1M, and we do not use it in our whitelist algorithm. In addition to the concerns raised by those researchers, we discovered that the Alexa lists do not hold the statistical properties expected in natural rankings, while all of the other sources did. In particular, when you place domain queries in rank order, the number of queries is known to be proportional to the rank itself; this phenomenon is called Zipf’s Law and is widely observed in natural systems ranging from city sizes to Internet traffic usage. Because the underlying count data of Alexa is not published, we inferred it from runs of alphabetically ordered items in its rank lists. Based on Zipf’s Law, we expect the length of these ‘runs’ to start small and increase proportionally as the popularity decreases. In other words, the less popular a domain is, the more likely it is to have been queried the same number of times as other unpopular domains. Aside from Alexa, we found that all sources based in ranking by counts behave exactly in this way. In the image below, you can see a comparison of the runs of a DNS data source with that of Alexa. Because Alexa does not follow expected statistical behavior, we have no way to determine how it was generated.
In [3] the authors identified additional types of irregularity with Alexa and similar data sources. They attempt to deal with these issues by combining all of the ranking sources into a single list. Each data source is modeled with Zipf’s Law and the resulting inferred values are summed. At first glance, this seems reasonable. However, it is not actually based in statistical science due to the fact that it is simply not possible to add rankings together from different sources. The result would be a ranking list that is manufactured in a way that is still inherently flawed. The authors have made heuristic adjustments to their rankings in an attempt to stabilize them, but different data sources ultimately can’t be merged into a single ranking.
As a result of this research, and our concern with the integrity of domain ranking lists as an integral ingredient in cyber threat intelligence, we built our own ranking product, Inforanks, recently introduced into the Infoblox Dossier threat research portal. Inforanks will provide not only a domain ranking, but will also include the confidence range, giving customers additional information necessary to understand a potential threat in their network. Inforanks is based on statistical sampling to create a ranking that is not based on a single point in time, but rather incorporates numerous days of activity. We will go more into the details of this algorithm in a white paper and future blog post.
In addition to Infoblox’s Smartlisting and Inforanks algorithms, we also assessed the potential of an outage to our customer’s network using an array of criteria, several of which are not tied to popularity. The resulting Risk of Enterprise Outage (REO) score is used as an additional filter in our threat feed framework and available for select threat properties via the Infoblox Threat Intelligence Data Exchange (TIDE). Together REO, Smartlisting, and Inforanks provide a suite of capabilities and are only the beginning of our commitment to protecting customers both from security threats and network interference.
[1] Renée Burton, Laura da Rocha, “Whitelists that Work: Creating Defensible Dynamic Whitelists with Statistical Learning,” 2019 APWG Symposium on Electronic Crime Research (eCrime), Pittsburgh, PA, USA, 2019, pp. 1-10, doi: 10.1109/eCrime47957.2019.9037505.
[2] Alexa Top Sites. the daily top1M is available for download at http://s3.amazonaws.com/alexa-static/top- 1m.csv.zip. URL: https://aws.amazon.com/alexa-top- sites/.
[3] Victor Le Pochat, Tom Van Goethem, Samaneh Tajal-izadehkhoob, Maciej Korczynski, and Wouter Joosen. “Tranco: A Research-Oriented Top Sites Ranking Hard- ened Against Manipulation”. In: Proceedings of the 26th Annual Network and Distributed System Security Symposium. NDSS 2019. Feb. 2019. DOI: 10.14722/ndss.2019.23386. URL: https://tranco-list.eu.
[4] Quirin Scheitle, Oliver Hohlfeld, Julien Gamba, Jonas Jelten, Torsten Zimmermann, Stephen D. Strowes, and Narseo Vallina-Rodriguez. “A Long Way to the Top: Significance, Structure, and Stability of Internet Top Lists”. In: CoRR abs/1805.11506 (2018). arXiv: 1805. 11506. URL: http://arxiv.org/abs/1805.11506.





