




Error propagates, but does it matter? Not unless the train is crashing through the station.
As the head of threat intelligence for Infoblox, I receive a lot of questions about both our intelligence and the process of threat hunting more generally. My background as a mathematician with nearly 23 years focused on delivering intelligence to decision makers, 6 years of that dedicated specifically to very-large-scale passive DNS analysis, has given me a broad perspective on the promise and reality of threat intelligence specific to DNS. This is the first in a series of occasional blogs designed to answer some of the questions I receive most frequently.
The most common question I hear is: “What is the false positive rate?” The short answer is “It depends,” which isn’t very satisfying. While this question sounds straightforward, it is impossible to answer accurately in large-scale data systems, and it is really the wrong question to ask. What customers really want to know is whether an algorithm is likely to negatively impact their business, either because their users are frequently unable to access what they need or they spend a lot of resources trying to verify security detections.
In our products, when a customer is unable to reach an important DNS resource, such as a website, due to a false positive, this is a negative impact. We learn about negatively impacting false positives through our customers in requests to remove a specific domain or IP address from our Response Policy Zones (RPZs) used in DNS Firewalls. We measure negative impact directly through customer feedback. During 2022, our RPZs included 32M unique indicators from original intelligence, and we had a reported false positive, negative impact rate of 0.00015%.
Many of these false positives are from statistical or machine learning algorithms. Users are often frustrated that something that seems obvious to them isn’t picked up by the algorithm. In this article, I explain how: 1) false positives from machine learning algorithms can be magnified due to the environment, 2) the application environment can work against us, and 3) counterintuitively, how we can see more false positives in a “cleaner” network. False positives in threat intelligence also come from other sources than algorithms, including the use of sandboxes, applying indicators of compromise outside of the intended context, and inappropriately associating indicators together, but we will leave these topics for a future blog.
Machine learning and statistical algorithms play an important role in threat intelligence when leveraged appropriately. From this article, I hope you will have a better intuition for how false positives occur and can be magnified by the environment. For users, adopting an impact-based decision criteria over a naive false positive rate will give you more security. For data scientists, you will see how an algorithm that tests well can perform poorly in practice. In all cases, the performance of these algorithms has to be evaluated in the wild and not in the lab.
As an example, we, and several other vendors, in response to the tragic earthquakes in Türkiye and Syria, detected a domain registered directly following the event as malicious. In order to provide a rapid response to protect consumers, threat intelligence groups use features of domains to identify potential phishing. The domain registered by DCipher Analytics was privately registered, contained keywords expected for phishing after a disaster, was registered on a highly abused TLD, and with a highly abused registrar and hosting service. Let’s walk through a hypothetical situation to see how these false positives happen.
False Positives in Machine Learning
We will use an application to detect malicious domains for illustration, but the same principles apply regardless of application. Suppose we have an algorithm that will detect 80% of all malicious domains. All statistical or machine learning algorithms have some error because they inherently involve probabilities. Our algorithm will incorrectly label a legitimate domain as malicious 5% of the time; this is the error that creates false positives. While false negatives, which occur when malicious domains are not detected, are also an important kind of error, they are not the focus of this article. Before reading on, think about your requirements for the algorithm’s performance. What is your expectation of the false positive rate?
Now, let’s consider the algorithm’s performance in two different environments.
I’m going to borrow an illustration from the book Statistics Done Wrong.1 First, assume that 20% of all the domains in a data set are actually malicious. For demonstration, we use a set of 50 domains. We calculate that:
- There are 10 malicious domains in the data, and our algorithm will find 8 of those
- Of the remaining 40 legitimate domains, our algorithm will incorrectly think that 2 of those are malicious
- We detect a total of 8 + 2 = 10 domains as malicious in the dataset
In Figure 1 below, we show these results as shaded and labeled squares. The algorithm would detect both the green (“right”) and red-shaded (“wrong”) squares as malicious.
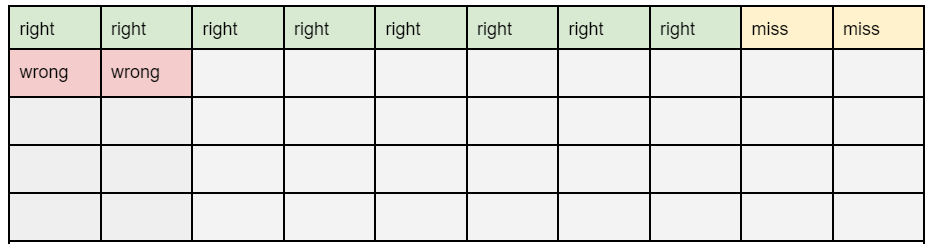
Figure 1. An illustration of algorithm performance on 50 domains. Our algorithm finds the squares marked in green/”right” and red/”wrong” from the full dataset of fifty domains, which is 8 of the 10 malicious domains. It missed two domains (marked in yellow/”miss”), and it falsely identifies two legitimate domains (marked in red/”wrong”) as malicious. The remaining, marked in gray, are legitimate. Each row contains 10 domains.
In this scenario, the algorithm looks pretty good. It detects 10 domains as malicious and 80% of these are truly malicious. But, it also detects 2 legitimate domains as malicious, meaning the false positive rate is 2/10 or 20%. So the false positive rate, or false discovery rate, in this environment is 20%, where you might have expected, say, 5% based on the description of the algorithm. If your network only has 50 domains, this isn’t too bad, but when the detector processes tens of millions of domains, there will be millions of false positives.
Unfortunately, in DNS, the numbers are against us.2 Not only are we dealing with very large data volumes, but the percentage of malicious domains is significantly lower than 10%. Experts disagree on the figure, but to carry forward our example, let’s assume that 5% of domains were malicious and instead of 50 domains, we were considering 1 million. Using the same calculations:
- there are 50k malicious domains in our data and the algorithm will detect 40k of these (in green/”right” below)
- with a 5% false positive rate, of the remaining 950,000 legitimate domains, the algorithm will falsely predict 47,500 are malicious (in red/”wrong” below)
- we detect a total of 87,500 domains in the dataset as malicious (green + red squares)
This is shown proportionally in Figure 2 in which every row represents 100k domains, and each cell has 10k domains.
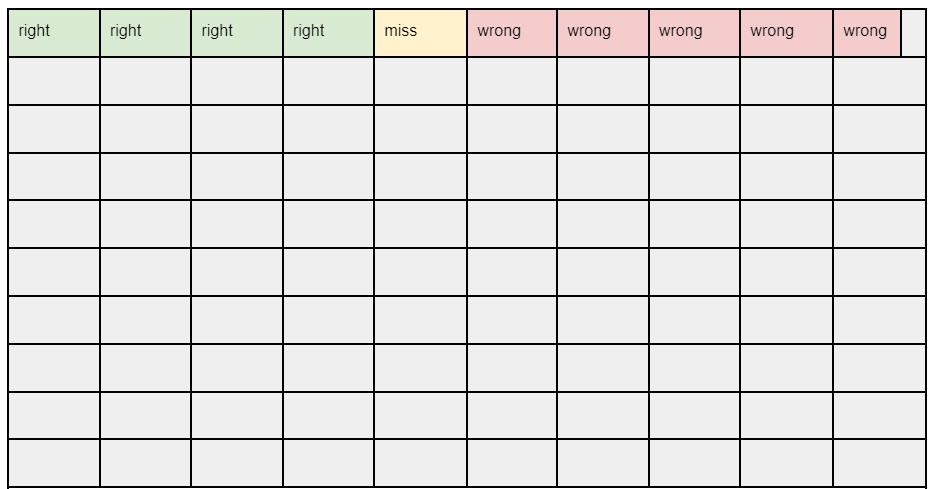
Figure 2. The false positives exceed the true positives when there is a large amount of data and a small percentage of malicious domains within the data. Here 5% of the 1M are truly malicious (green + yellow/”miss”). Our algorithm catches 80% of the malicious domains (marked in green) and misses 20% (marked in yellow). It incorrectly finds 5% (marked in red) of the legitimate domains to be malicious. The remaining (marked in gray/unlabeled) are legitimate. Each row has100k domains.
Wait! What happened?!! The algorithm detects 80% of malicious activity and now the false positives outnumber the true positives?! Our algorithm has a false positive rate of 54% in this scenario! How can that happen? False positives are an error proportional to the legitimate sample size, and the false positive rate is impacted by this error, as well as the level of imbalance between legitimate and malicious domains. The greater the imbalance is between good and bad things, the more our false positives weigh within our detections. Les choses sont contre nous.

This is a classic example of error propagation: the larger our data, and the more extreme the imbalance, the greater the error. In cybersecurity, regardless of whether your analytic is running on domain names, URLs, netflow, or any other kind of network-related data, the volume will be large and the imbalance between legitimate and malicious activity will be extreme. Infoblox handles over 30 billion DNS requests at our cloud resolvers every day, containing hundreds of millions of domains never seen before in our network. The inset image shows the result of error propagation that led to the 1895 Montparnasse train derailment.3
So does that mean machine learning has no role in cybersecurity? Absolutely not. We, and many other vendors, effectively use both machine learning and statistical learning analytics in the detection of threats. But both those within the industry and our consumers should manage their expectations of what even the most powerful algorithm can do at scale. Those entering the field of data science, and researchers in academia, hoping to find the perfect mix of features also need to realize that the scales, and the level of imbalance, on which researchers typically train algorithms is far lower than is found in the wild. Ultimately, error is unavoidable and it propagates.
Conclusion
As you’ve seen here, threat intelligence performs differently in different environments. “What is your false positive rate?” is the wrong question. If false positives don’t impact your network and resources negatively, then they really shouldn’t matter. Johns Hopkins University Applied Physics Lab (JHU/APL) calls this the low regret methodology for adopting intelligence.4 They have piloted threat intelligence feeds across multiple critical infrastructure communities and advocate for impact, both positive and negative, as a measure for success rather than attempting to quantify false positives. In my role, and with my background, I strongly believe this is the correct approach to securing a network as well. Furthermore, it is important to use intelligence sources that are designed for your environment. At Infoblox, we design intel specifically for use in a DNS environment in order to provide the most relevant protection to our customers.
Returning to my comment at the start of this article, Infoblox had a reported false positive rate of 0.00015% in 2022. This means our customers reported negative impacts for 1 in 543,000 unique indicators in our RPZs. How does Infoblox achieve such a low reported false positive level? The intelligence that feeds our RPZs includes detections from a wide variety of algorithms, some of which are statistical in nature, and some of which are not. We also utilize human-in-the-loop strategies for high-risk algorithms and for threat hunting. Multiple layers of processing help remove potential false positives, and we age out indicators that may no longer be a threat. The process concludes with a patented algorithm that identifies domains critical to our customers and removes them from any RPZ.5 This combination allows us to provide customers maximal protection with minimal negative impact. We have over 13 million active high threat indicators in our RPZs as of early February 2023.
Endnotes
- Statistics Done Wrong, The Woefully Complete Guide, Alex Reinhart, No Starch Press, 2015
- “Les choses sont contre nous” https://en.wikipedia.org/wiki/Resistentialism
- https://en.wikipedia.org/wiki/Montparnasse_derailment
- https://github.com/JHUAPL/Low-Regret-Methodology/blob/main/README.md#introduction
- https://blogs.infoblox.com/security/going-beyond-whitelists-smartlisting-is-required-for-the-modern-enterprise/


