




As digital threats accelerate in both volume and complexity, and as AI-enabled threat actor development will surely further deepen this existing asymmetry, human analysts often struggle to synthesize the sheer volume of intelligence in a timely manner. Existing methods for open-source intelligence (OSINT) investigation often rely on manual report synthesis (locating, reading, operationalizing), which cannot easily scale to meet rapidly evolving threats. Meanwhile, the industry-wide surge in ”agent” conversations has left some defenders feeling empowered and others feeling disillusioned by the hype cycle. There is little doubt that autonomous workflows will introduce a significant transformation in how adversaries and defenders engage in the age-old cybersecurity game of cat and mouse. To this end, we hope this paper will help defenders operationalize agentic concepts to strengthen their security and business operations.
We introduce Blue Helix, an agentic OSINT platform that aims to alleviate manual collection and synthesis pressures by intelligently searching the web, ingesting threat reports, extracting the most salient data to support Infoblox’s OSINT requirements, and adapting its search strategies. This multi-agent system is built using OpenAI’s Agents SDK, Playwright browser orchestration, multiple large language models (LLMs), optical character recognition (OCR), and a genetic algorithm inspired by the biological principles of evolution. Blue Helix determines its mode of operation by plotting and reviewing key performance metrics in real time, which it interprets to decide if it should explore new search terms for discovery or exploit previously successful queries through its use of a genetic algorithm. This evolutionary learning process represents a significant innovation in autonomous threat intelligence research, blending the art and science of information gathering while balancing expansive exploration with focused exploitation of verified methods. The outcome is a system that operates at scale while delivering targeted insights tailored to Infoblox’s strategic objectives and broader cybersecurity goals.
Technical Architecture
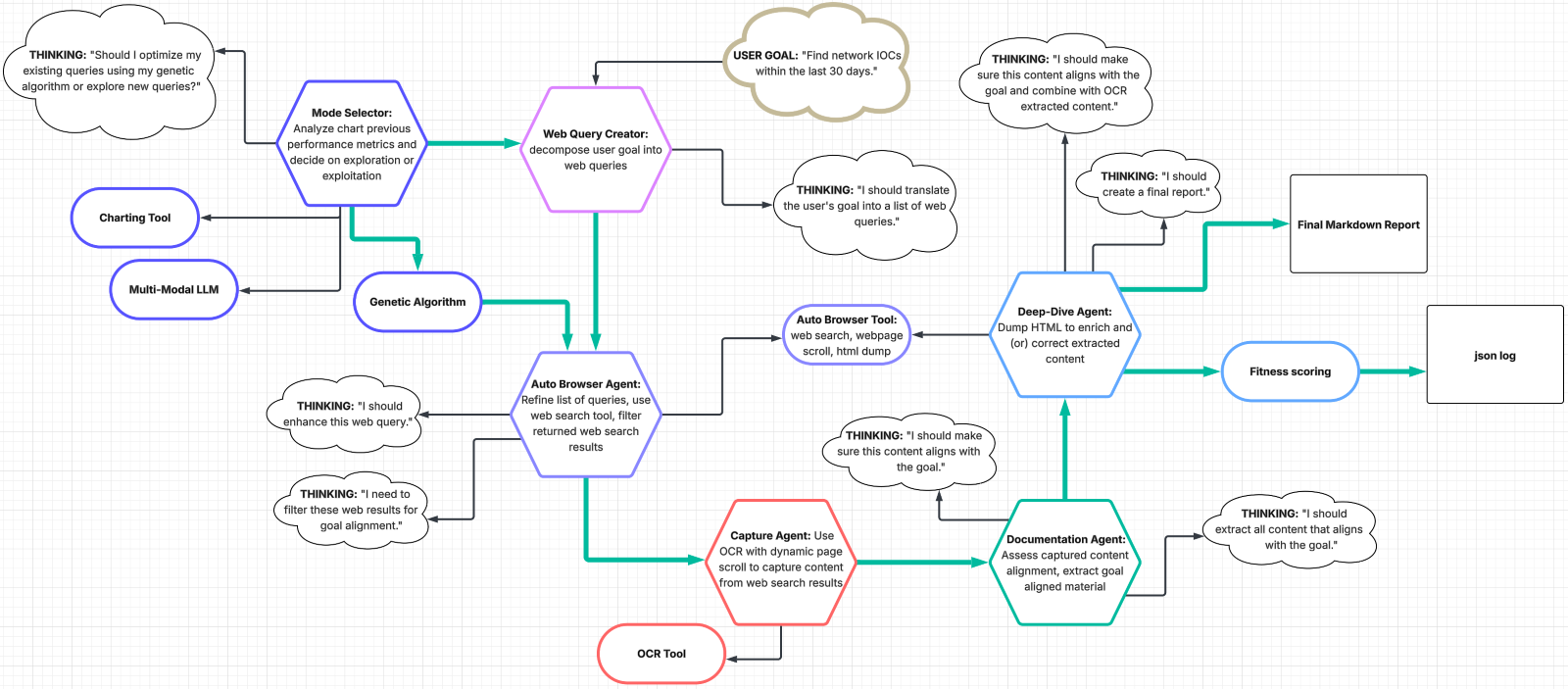
Figure 1. Blue Helix technical architecture
Multi-Agent Environment
Our first experimentation with OpenAI’s Agents SDK proved quite fruitful. According to OpenAI, the Agents SDK ”enables you to build agentic AI apps in a lightweight, easy-to-use package with very few abstractions,” and we found that it lived up to this promise. We were particularly impressed, though not entirely surprised, by the fact that the agents were clearly optimized to integrate with the OpenAI models we used (o3-mini and 4.1).
Blue Helix incorporates a multi-agent environment, but not in the typical sense where each agent has full autonomy in a strictly hierarchical or decentralized setup. Instead, Blue Helix both leverages and constrains the probabilistic reasoning and acting (ReAct) paradigm, capturing the best of both worlds: repeatable outcomes where consistency is needed and agentic decision-making where adaptability is most beneficial. This constraint is reflected in the architecture as a clearly defined pipeline, with specific “forks in the road” where agentic decision-making comes into play, such as determining an operational mode (explore versus exploit) based on performance evaluations. Further autonomy is harnessed within various sub-processes in the pipeline, for instance refining search queries based on active web search observations or filtering web results to maintain goal alignment and avoid overburdening subsequent investigative steps.
Lastly, it is not obligatory for every agent to have a broad range of tools to contribute significant value to the system. Instead, we find that a well-defined tool scope and compartmentalized agentic sub-components preserve a high degree of task-specific creativity, while also producing predictable results that are both easier to troubleshoot and more suitable for production environments. Some of the agents within Blue Helix operate without external tools, instead utilizing the SDK’s agent class for iterative reasoning cycles, fostering more refined outputs compared to just prompting an LLM for an outcome.
Operational Modalities and Adaptive Intelligence
Blue Helix represents a significant advancement in automated OSINT collection. At its core, the system implements a novel dual-mode operational framework that dynamically balances between exploration and exploitation strategies to optimize search effectiveness. This approach addresses a fundamental challenge in automated research systems: efficiently navigating the trade-off between discovering new information spaces and refining known productive pathways.
The agent chooses operation between two distinct modes: Goal-Based Generation (exploration) and Genetic Algorithm (exploitation). In Goal-Based Generation mode, the system emphasizes diversity and breadth in search strategies, generating semantically varied queries based on a predefined goal, to explore the information landscape. This mode is characterized by its ability to break free from local optima and discover entirely new regions of the threat intelligence space that may contain valuable indicators of compromise (IOCs).
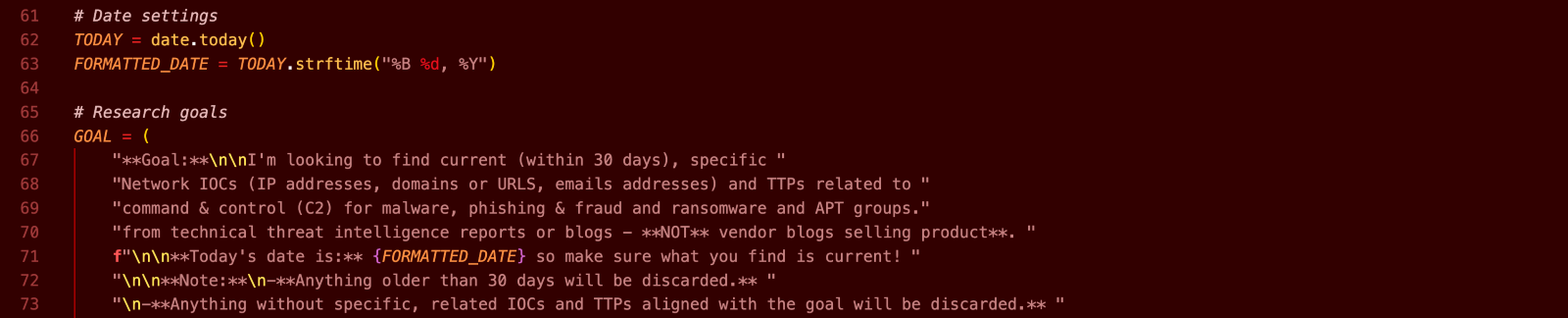
Figure 2. Blue Helix predefined goal
At the heart of the Goal-Based Generation (exploration) mode is the query planning agent, a module that transforms a user’s goal into a set of brief, targeted web queries—typically 25 to 30, each under four words. By leveraging the agent class’s innate reasoning, the query planner systematically rephrases, refines, and diversifies these goal-based queries, achieving exploratory coverage across the desired information space.
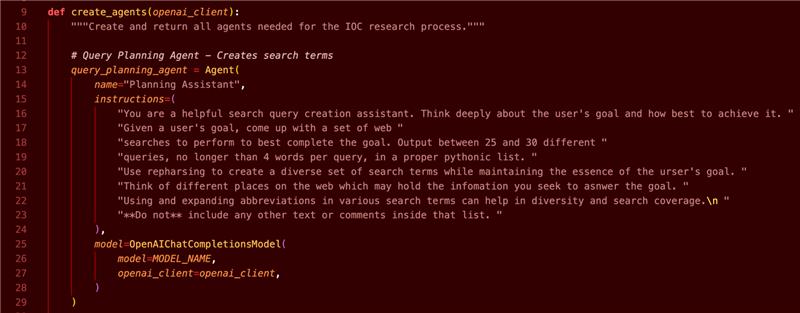
Figure 3. Instructions for goal deconstruction into web queries
Conversely, the Genetic Algorithm mode implements evolutionary selection principles to refine and optimize search terms that have demonstrated effectiveness. This exploitation-focused approach leverages fitness scoring based on IOC yield and search metrics, iteratively evolving search queries through selection, crossover, and mutation operations to maximize information extraction from productive terms (see section Genetic Algorithm).
A distinguishing attribute is Blue Helix’s capacity for self-optimization through autonomous mode selection. By continuously analyzing performance metrics (including IOC discovery rates, fitness scores, and search result patterns), the system employs a trend analysis mechanism to determine when to switch between exploration and exploitation. When the agent detects diminishing returns in the current mode, it will choose to switch modes. If the agent sees that it is preforming optimally, it will continue with the current mode until the performance has exhausted.
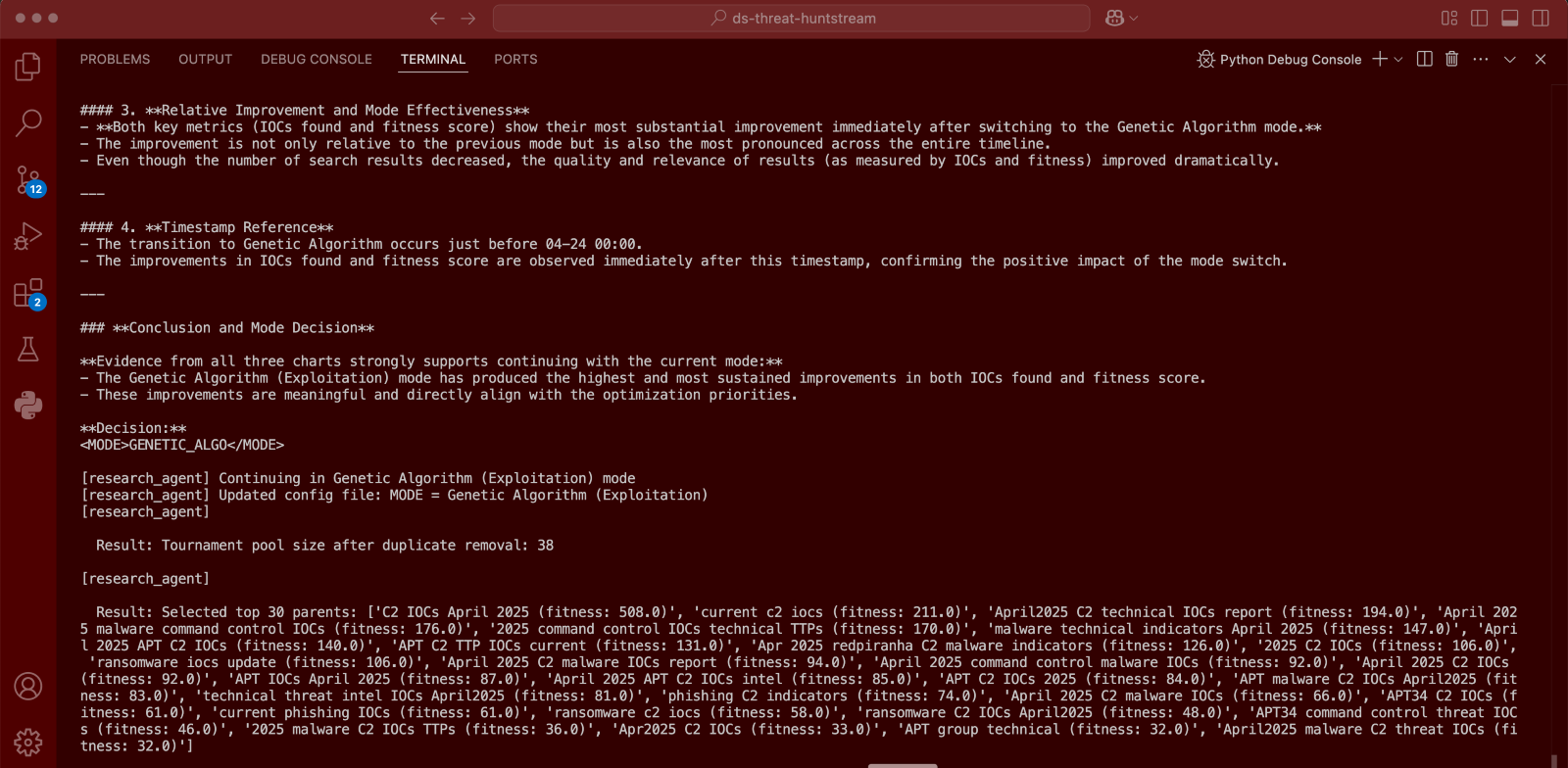
Figure 4. Blue Helix analyzing its performance and opting for continuing with exploitation mode
Genetic Algorithm
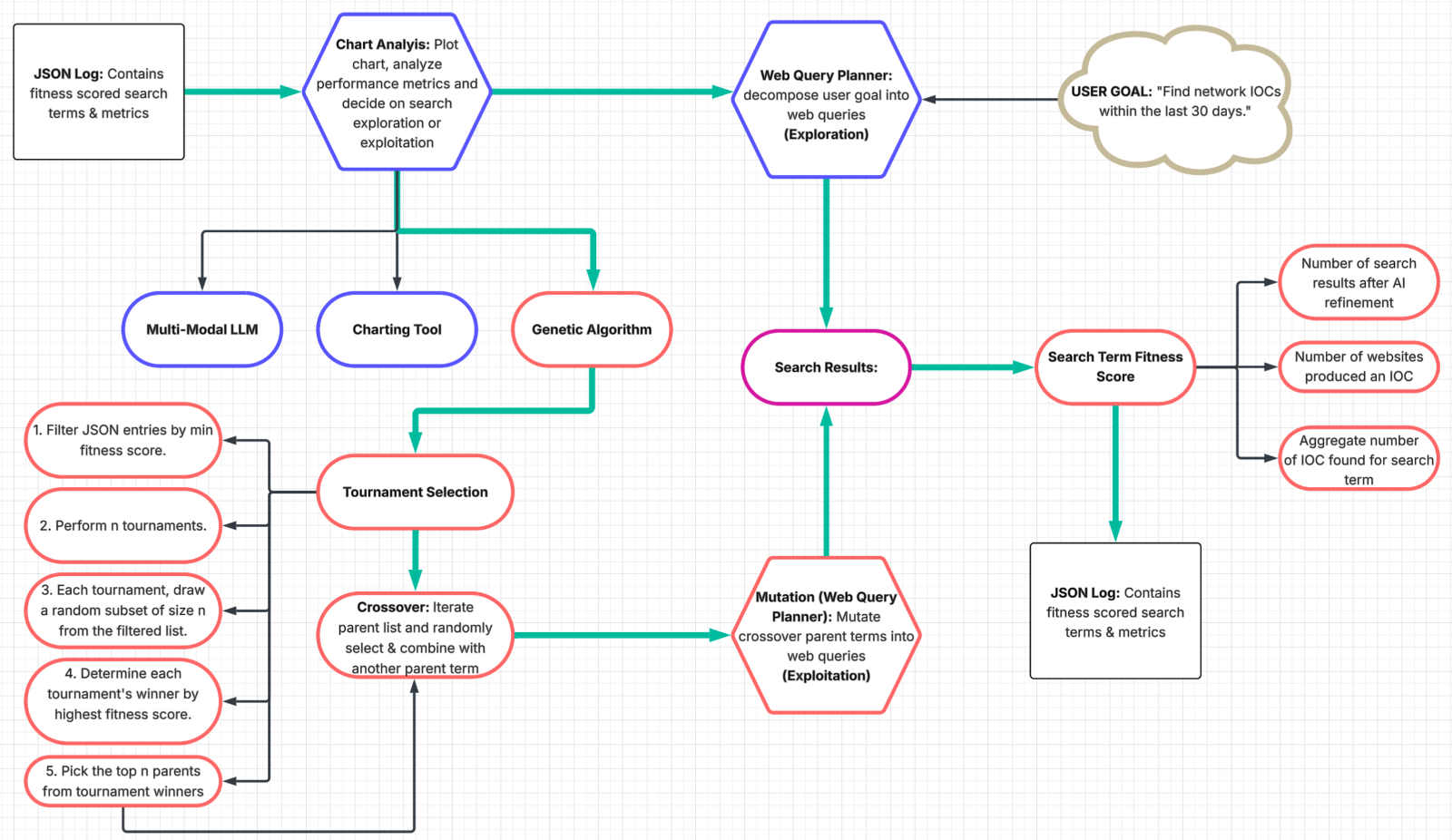
Figure 5. Architecture of genetic algorithm
Fitness Scoring
Initially the system begins in exploration mode, generating a population of search terms based on the goal and then scoring each term’s fitness. Each of these terms is run through the “calculate_fitness_score” method in the “GeneticAlgorithm” class, which assesses aspects such as the number of search results (post agent filtering) and the presence of observables or IOCs. The goal of the fitness score is to judge which of the search term population showed the most potential for locating high-value information.
Once a population is scored, Blue Helix logs these individual term entries to JSON, ensuring that performance metrics and relevant links are preserved. Blue Helix merges new findings with prior data (up to a defined date threshold), recalculating the fitness scores and associated data. This approach provides a rolling history that helps refine the overall search strategy; older entries get replaced, while fresh or frequently chosen search terms are iteratively improved to better reflect their latest performance.

Figure 6. Agent-derived search terms visualized by fitness score
Tournament Selection
Once performance declines the agent will decide to switch operational modalities, employing a genetic algorithm to select high-performing terms and optimize its search efforts. The “GeneticAlgorithm” class contains a method for tournament selection, an approach wherein random subsets of search terms “compete” based on fitness. Each tournament winner moves on to a next stage, ensuring that consistently strong or promising search terms bubble up to the top. This repeated process filters out less productive terms and elevates the ones that yield more IOCs and higher fidelity threat data. Finally, Blue Helix sorts the tournament winners pool by their fitness scores and selects the most performant parents to guide subsequent searches.
Crossover and Mutation
In the subsequent phase of Blue Helix’s genetic algorithm, the system initiates a rudimentary form of crossover by taking a seed search term from the parent population and then randomly selecting another parent term to “combine” with. This simple concatenation effectively merges two high-scoring candidates into a new sequence, capturing elements from both. While this simple pairing approach may not rank among the more advanced crossover strategies found in classical genetic algorithms, it nonetheless represents a direct means of melding information-rich search terms and amplifying the likelihood of discovering new intelligence leads after agentic mutation.
Following this crossover process, the system moves on to the mutation step. The relevant code snippet (below) illustrates the inclusion of a specialized ”Mutation Auto Browser Agent,” which takes the newly combined term and alters it based on instructions drawn from natural language transformations: rearranging words, substituting synonyms, or modifying the morphological form (e.g., turning “monitor” into “monitoring”). This ensures that even though the core ideas of both parent terms remain, the newly formed query can explore adjacent territory or dimensional expansions that might otherwise remain undiscovered.
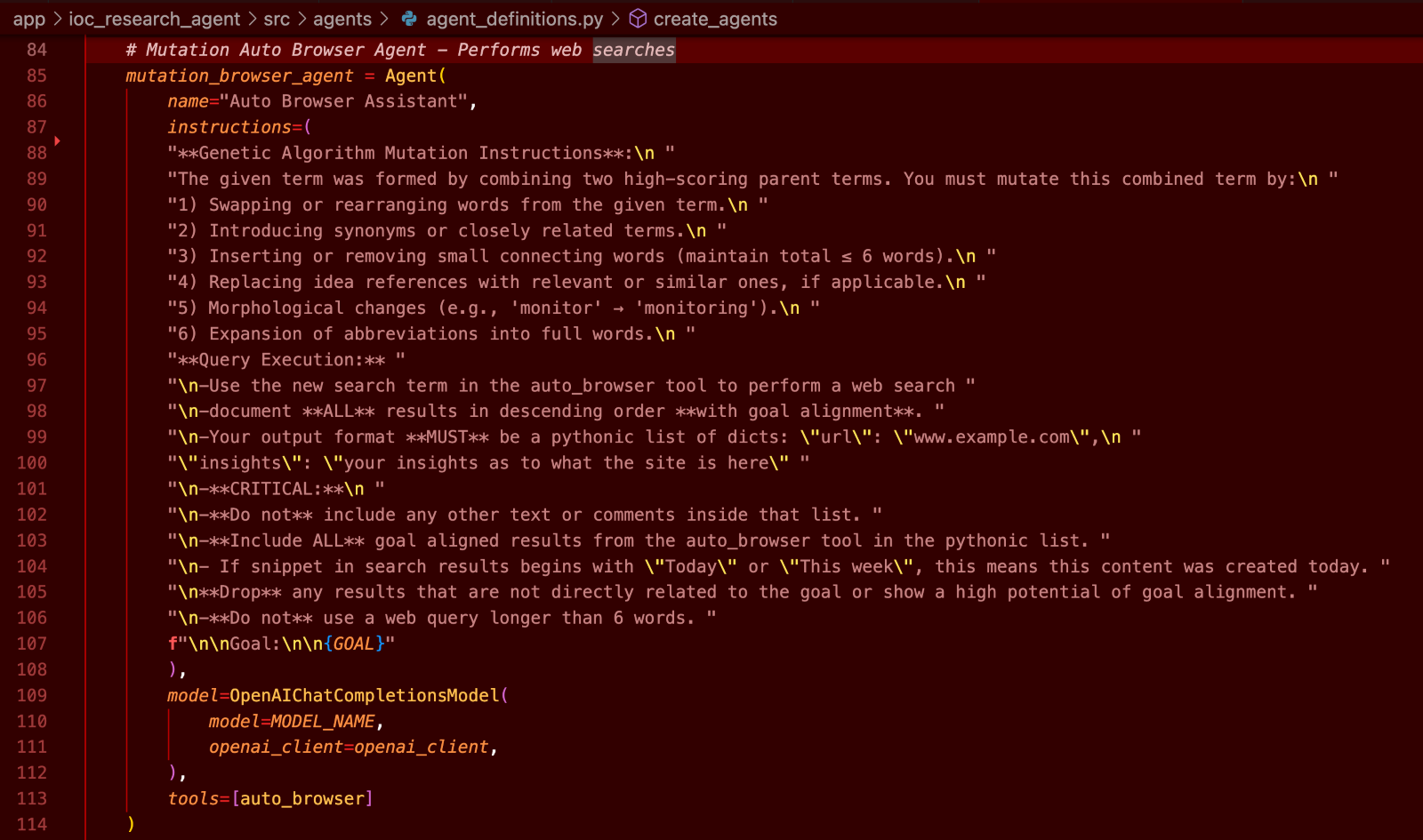
Figure 7. Mutation prompt
Once mutated, these new queries are run through the system’s search routine, and their performance (in terms of resulting search hits, pages with IOCs, or other meaningful signals) is recorded. This data subsequently feeds back into the fitness scoring function, closing the loop and allowing Blue Helix to iteratively improve its search terms. Over multiple iterations, parents are continually produced, cross-bred, mutated, and re-evaluated, ultimately guiding the system toward progressively higher-fidelity and more potent queries.
This mutation approach powerfully engages an agentic process, one that leverages natural language understanding to invoke more meaningful or context-aware mutations. Moreover, each mutation is subsequently tested against real-world search engine behaviors, making the genetic algorithm’s adaptation loop that much more dynamic.
Agent Tools
Blue Helix leverages a robust “AutoBrowser” class built on top of Playwright to automate web navigation and content extraction, serving as the foundation for a variety of specialized web research tools. This orchestration layer makes use of Firefox under the hood to perform targeted web searches, browse to pages of interest, and handle scrolling to reveal content beyond the initial viewport.
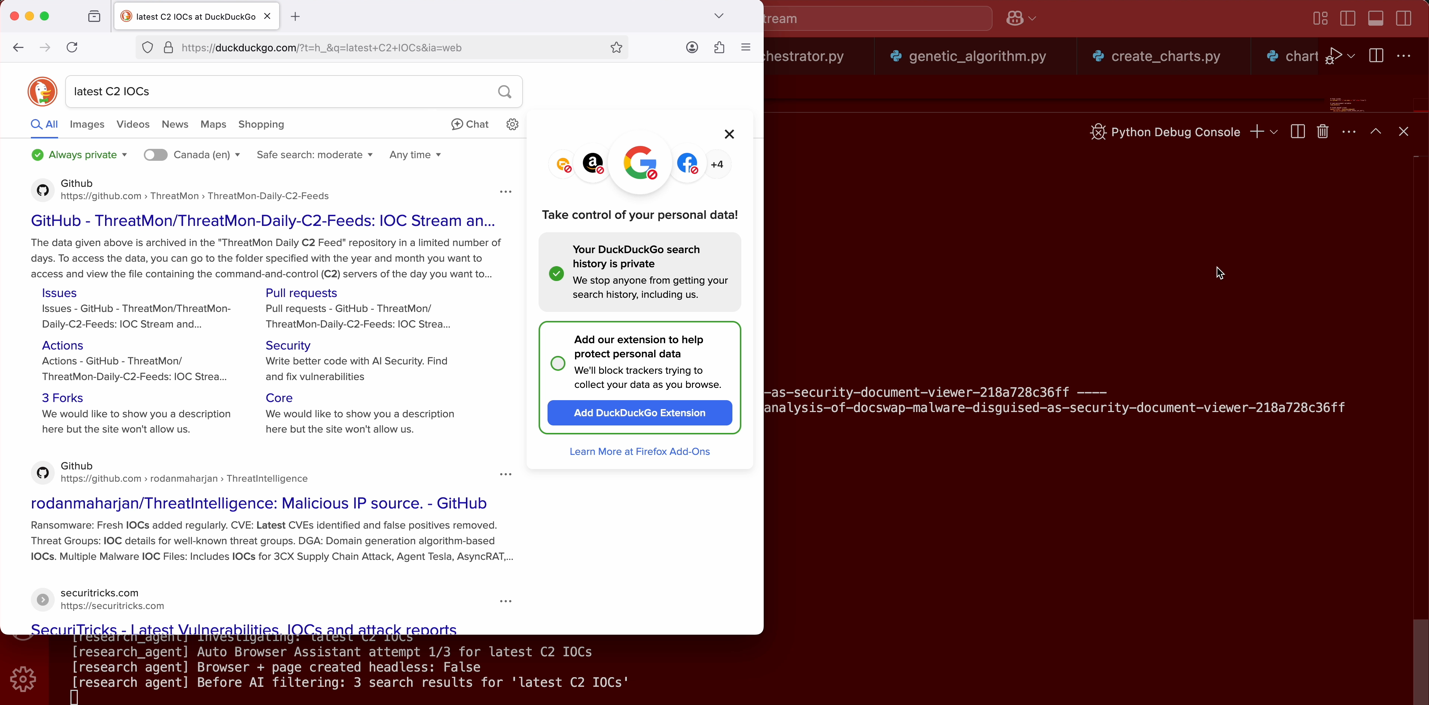
Figure 8. AutoBrowser class Duck Duck Go web search
A core capability within this class is the handling of large or complex pages. Instead of relying on a single static capture, the “capture_large_page” method scrolls through the content, taking multiple screenshots as it progresses. These images are then processed through Optical Character Recognition (OCR), allowing Blue Helix to retrieve high-value information that might otherwise remain hidden beneath long scrolls. Further, IOCs often appear in diagrams and embedded visuals, which are also extracted through this OCR-based approach.
Complementing OCR capture, the system’s “html_dump” method utilizes “BeautifulSoup” to parse and clean raw HTML content. This ensures that, in addition to images, standard textual data is thoroughly extracted and cleaned for analysis. When OCR occasionally introduces transcription errors, parsing the HTML can correct or reinforce data accuracy, offering a comprehensive perspective that merges both native and image-based text.
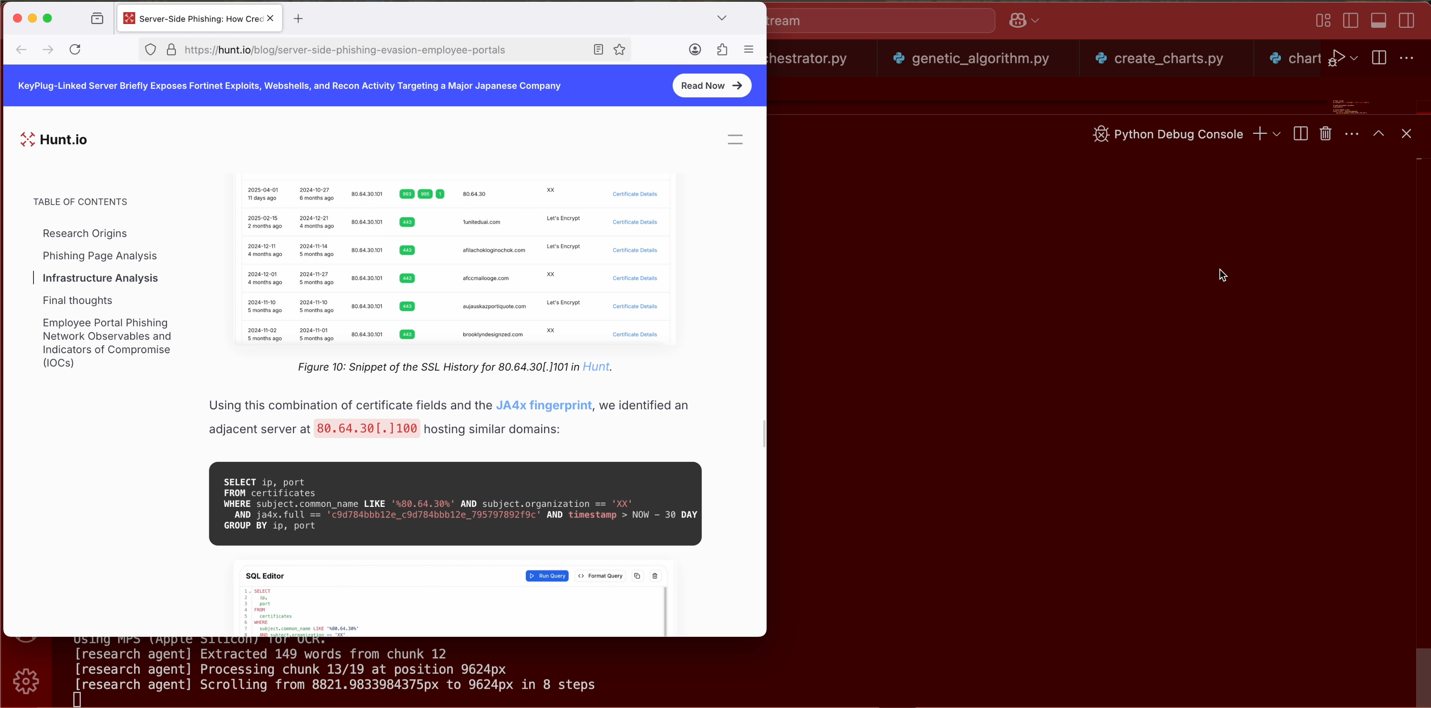
Figure 9. AutoBrowser class scrolling large content with OCR chunking capture
Another core feature is the PDF handling mechanism. Blue Helix first attempts a direct file download, using PyPDF2 to extract text from each page. If that fails due to server settings or file formats, “AutoBrowser” transitions seamlessly to a fallback: loading the PDF in a browser window and applying OCR to the rendered pages. This dual setup extends coverage to a diverse array of documents—ranging from PDFs and HTML files to image-based resources—enabling comprehensive data extraction for thorough IOC research.
In addition to its web navigation and content capture capabilities, Blue Helix includes a dedicated plotting and analysis suite designed to visualize and interpret OSINT results in real time. By logging search terms, fitness scores, and contextual data to JSON, this module leverages libraries like “matplotlib” to analyze stacked trend lines reflecting IOC detections, fitness scores, and overall search results. The core “ChartAnalyzer” class further supports detailed examination of mode transitions (e.g., exploration versus exploitation), automatically Base64 encoding chart images for downstream AI-based analysis and mode decision recommendations.
Report Generation and Goal Alignment
Blue Helix applies robust goal alignment checks at multiple points to ensure that only relevant information proceeds to deeper analysis. During the web search process, the AutoBrowser agent first filters out any links already investigated, then evaluates new results against the overarching goal to determine whether further examination is warranted.
Following OCR-based text capture, the Documentation Agent introduces a second gate: it validates the extracted text for relevance, discarding any segments that fail to align with the system’s targeted objective. If no captured content is goal aligned, the Documentation Agent skips the content altogether. This stage helps to prevent unrelated material from overburdening subsequent analysis.
A final gate occurs when the Deep Dive Agent dumps and parses the HTML content. It mirrors earlier checks by evaluating text for alignment before creating the finalized report and adding it to the output feed. Removing irrelevant content here ensures that only information of measurable value will appear in the deliverable output.
Ultimately, Blue Helix aggregates a markdown-formatted feed with details that focus on newly identified network IOCs within a 30-day window, along with the associated threat actors and campaigns, if present.
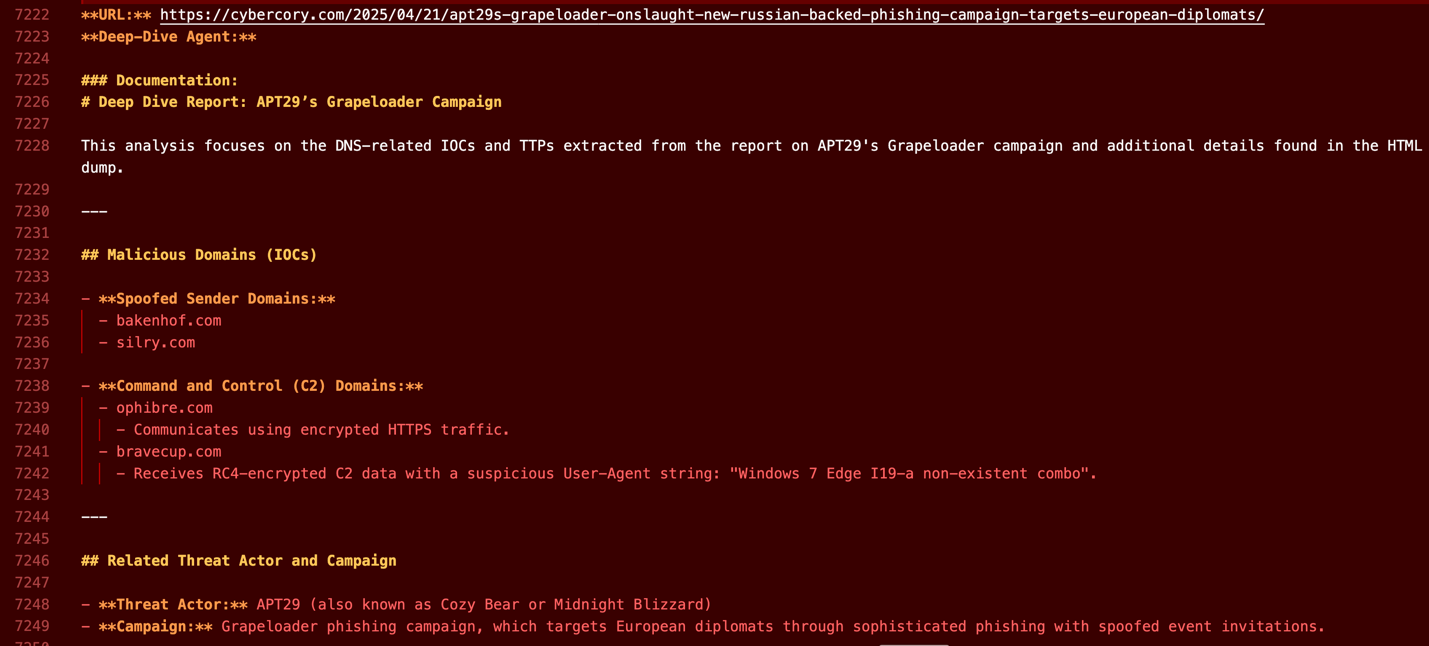
Figure 10. Markdown report with extracted IOCs, actor, and campaign
Operationalizing
At this stage, Blue Helix has identified OSINT, reviewed it, and extracted IOCs, threat actors, and campaigns. Next, we wanted to see how we could streamline the operationalization process. As part of a human machine teaming project, we developed Model Context Protocol (MCP) connections to internal databases. We developed a second agent capable of using MCP servers to research the indicators identified in our internal databases and apply updates/inserts to the database as called for by the first agent’s research efforts.
The summarized markdown reports are placed in a queue for processing by the second agent, whose role is to research the indicators using the MCP and process them into human-reviewable and actionable objects. In our case, the agent fills out indicator submission forms identical to those used by human analysts and places them into a “pending” state. This allows human reviewers an opportunity to make any edits, approve, or reject a submission with ease. This process enables rapid value extraction from the autonomous researcher and facilitates a feedback system to improve the prototype. As with any “new hire,” over time as we observe and gain trust in Blue Helix, our intention is that its submissions will immediately become active in the database without the need for review, and its capabilities increased.
The MCP server allows the agent to create high-quality submissions to the database and contains basic tools to search for indicators, actors, and indicator presence in customer networks. It also provides functionality for checking our internal allow list, checking the list of existing metadata tags for indicators, and preparing submissions to the database. For human users, the MCP server also exposes a few prompts as slash commands to easily facilitate common workflows with the support of sophisticated and optimized prompting strategies.
Though the MCP server at its core is wrapping already existing API infrastructure, we apply several optimizations to make their responses more friendly for an AI agent. For example, update dates are transformed to “days ago” to avoid the agent having to calculate this on the fly; responses are paginated to avoid flooding the context window; and large bulk queries generate a summary in addition to the raw results such as “Found 10 of 15 SLDs in customer traffic in the last 7 days” to reduce the cognitive load on the agent as it is generating a final submission summary. We also default some of these tools to “summary only” mode and call the non-summary mode outside of agentic chains when we want to build a report.
We found it useful to force the agent to start midway through a chain of tool calls. We know from experience that virtually every investigation should include checking presence of indicators in our database, allow list, and customer traffic; looking up valid metadata tags; and sampling indicators to give the agent an idea of the writing style in the freeform fields. When the input is known and a task is being automated, forcing these tool calls and starting the agent midway through a tool chain saves tokens, time, and avoids the risk of the agent going “off script” and skipping a critical research step. After these are performed, the agent knows that it should paginate additional indicator samples if the samples returned were updated recently, and we have instructed the agent to be persistent about actor searching so we can properly attribute indicators to actors. Finally, the agent generates a submission and an accompanying report to explain its decisions and the status of the indicators in customer traffic.
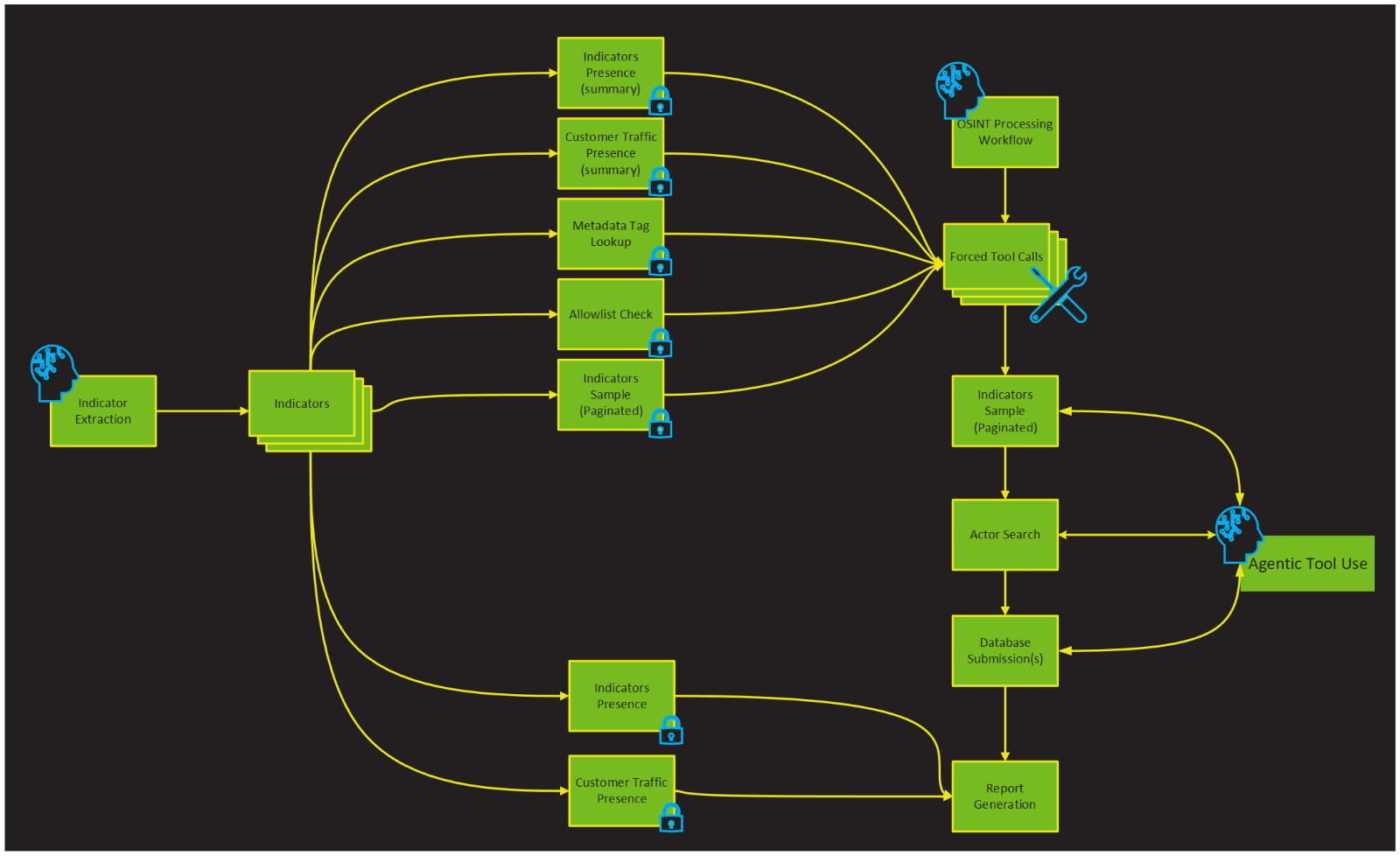
Figure 11. Indicator processing architecture diagram
In one example, the agent started by searching the database by name for “ColdRiver” (a Russian APT group). The initial search yielded no result, but the agent decided to search all actor descriptions for “Russian”: which, as you can imagine, yielded quite a few results. In one of them the agent found the following snippet:
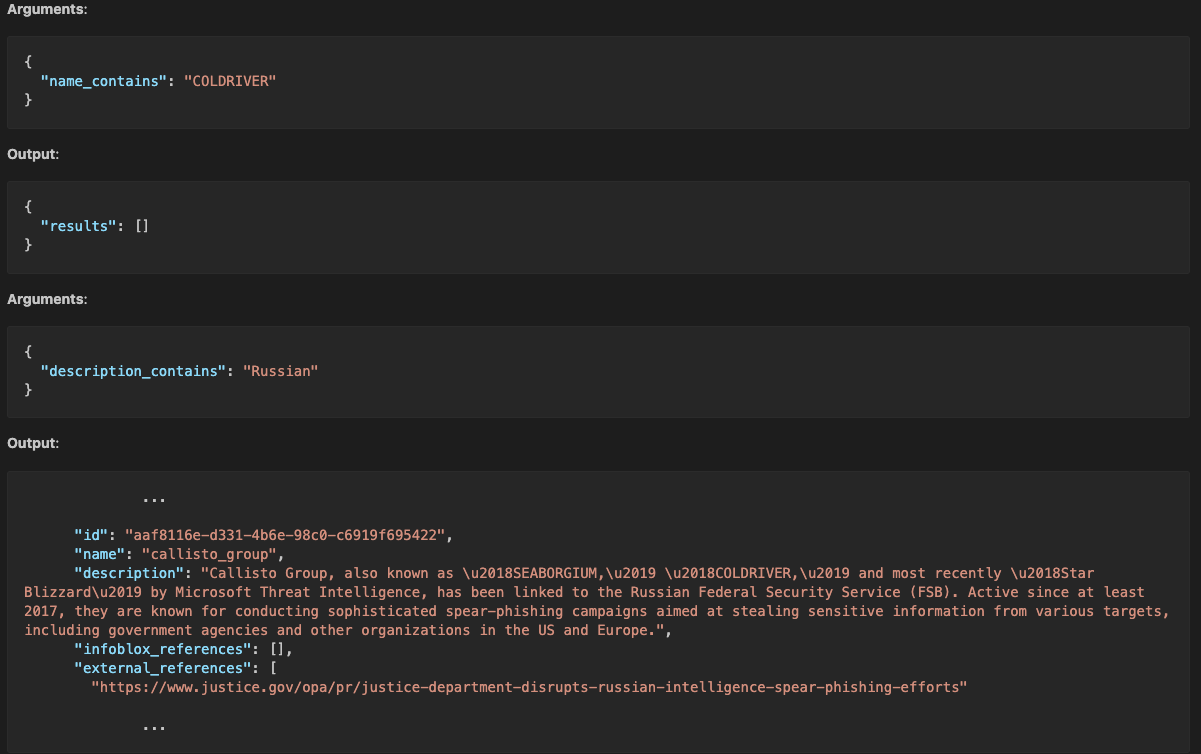
Figure 12. Actor searching results
This was enough for the agent to properly attribute the indicators to this FSB-linked actor group. In another, the agent searched for “Devman” and found nothing by name, so it decided to check for descriptions containing “ransomware” since the intelligence indicated that Devman was a ransomware group. Again, as you can imagine, there were a lot of actors associated with ransomware in our database; but this time the agent sifted through their descriptions and found none matching the description or the specific name Devman. In its final summary report, the agent mentioned that “If a Devman threat actor object is added in the future, linking these indicators is advised.” We have not yet allowed the agents to create actors themselves, but in the future, we expect this would be a case where the agent would do so.
Conclusion
Blue Helix was conceptualized to address the information overload defenders face, heightened by the speed and volume of modern cyberthreats. As discussed in our introduction, human analysts are often overwhelmed by the sheer volume of intelligence scattered across open-source platforms, and traditional methods for manual report synthesis can no longer keep pace. Blue Helix strives to fill this gap, automating the most repetitive elements so analysts can focus on the higher-level tasks that truly demand human expertise.
Building on the problems outlined earlier, Blue Helix offers a practical demonstration of how agentic concepts can translate into tangible cybersecurity benefits. By orchestrating multiple AI-driven tools (like OCR, web orchestration, genetic algorithms, and LLMs) within a well-defined, multi-agent environment, the platform alleviates the bottleneck of sifting through endless data resources. This approach empowers defenders, enabling them to capitalize on the speed and adaptability of machine intelligence while retaining human oversight where it matters most.
Crucially, the system’s dual-mode framework balances exploration and exploitation, a step toward more adaptive intelligence that can both discover new threat landscapes and deepen its search around known high-yield queries. Streamlined workflows including incremental page captures, automated PDF parsing, and meticulous alignment checks, showcase how Blue Helix systematically guides relevant data through the pipeline without overloading subsequent processes. The result is a targeted, markdown-based final report that not only offers immediate visibility into emergent IOCs, but also supports downstream integrations with Infoblox databases and other security tools.
Ultimately, this synergy between automated pipeline orchestration and thoughtful agent design marks a significant stride forward in OSINT collection. By operationalizing agentic thinking in a manner that helps defenders keep up with the accelerating velocity of threats, Blue Helix stands as a proof of concept for how the industry can meaningfully leverage these newfound technologies. While ongoing refinements will further enhance its capabilities, potentially removing the remaining human approval gates, its core architecture underscores the enduring need to unify speed, precision, and adaptability in modern cybersecurity.



