




Introduction
So, let’s suppose that you’ve been allocated a block of IPv6 addresses. If it’s your primary allocation, I’m hopeful that you’ve both encountered and taken to heart one critical address planning principle. This principle recommends that your primary allocation be sufficiently large enough to meet your addressing needs for the next several decades – say, 20-50 years. And chances are, that timeframe exceeds the likely lifespan of the Internet Protocol. (If you haven’t yet obtained an IPv6 allocation you can learn more about how to do so from ARIN’s website.)
This blog deals with the most familiar methods available for assigning subsets of address space from that primary allocation. And of course the same methods will continue to work when assigning space from within those subsets of assigned space as well (wheels within wheels!). These methods will work for any IPv6 allocation size (though as we will see as we explore the different allocation methods, some of them make more sense to use with larger allocations and some with smaller).
You’re likely already familiar with this process of assigning address blocks from your work with IPv4. But chances are due to the natural constraints on the availability of IPv4 address space, you may not be as familiar with a couple of the more commonly used address assignment methods the abundance of IPv6 address space allows for.
Four Common IPv6 Assignment Methods
Let’s begin with defining four common IPv6 prefix assignment methods. They are:
- Next available
- Sparse
- Best fit
- Random
To demonstrate how each of these methods works, I’m going to pick different allocation sizes. These sizes range from a /64 up to and including our primary allocation (the one we would get from a Regional Internet Registry or ISP to meet all of the IPv6 addressing needs for our entire network). If we’ve been paying attention to proper IPv6 address planning principles, we might hope that our overall primary allocation has a couple of beneficial characteristics. I’ve already mentioned that our primary allocation needs to be sufficiently large to accommodate the growth of our network more or less indefinitely.
Another beneficial characteristic would be that our primary allocation falls on a nibble boundary. It should probably also go without saying that such an allocation won’t be smaller than the smallest legally assignable prefix in IPv6 of a /64 nor larger than the largest allocation we’re likely to receive from a Regional Internet Registry. This largest size might vary but from personal experience wouldn’t likely be greater than an IPv6 /24.
Somewhere in between these largest and smallest allocations lies the /48, which we should recognize as significant for being both the recommended baseline size for a particular site within our network as well as for being the smallest Internet-routable prefix size. In my book, IPv6 Address Planning, I make a distinction between something I rather blandly referred to as inter-site vs. intra-site planning and this, in the briefest of nutshells, is the distinction between handing out address blocks from our primary allocation (something larger than a /48 if our network has more than one site – and nearly all networks requiring the architecture, engineering, and administration that keep us employed typically do) and handing out address blocks from within a single /48.
While any of our address allocation methods would theoretically work for either intra-site or inter-site planning, we’ll soon see which particular methods are more commonly used for each type of planning.
With all that in mind, let’s return to defining the first of our most common IPv6 address assignment methods.
Next Available
This method is alternatively referred to as sequential or monotonic. It’s best demonstrated by beginning with an allocation that is subsequently divided into smaller prefixes of identical size. For the purposes of making our example practical, we’ll start with the smallest nibble-boundary-aligned prefix that doesn’t directly go on an interface – which would be (and here we pause for an exercise briefly left to the reader)…
….that’s right, a /60! Hopefully, you’ve gotten familiar enough with your nibble math at this point that you recognize that a /60 provides you with…
…again correct, 16 /64s for interface assignment!
And so back to next available assignment. With all this cogitation, you can probably guess how it works given a /60 contains 16 /64s. First, let’s enumerate the prefixes we have available. To do this, I’ll use a handy little Perl tool called ipv6gen. It enumerates the IPv6 prefixes from a larger allocation. I’ll use a /60 arbitrarily derived from the documentation prefix (2001:db8::/32). The arbitrary allocation is 2001:db8:2112:1230::/60 and the following show the /64 breakdown: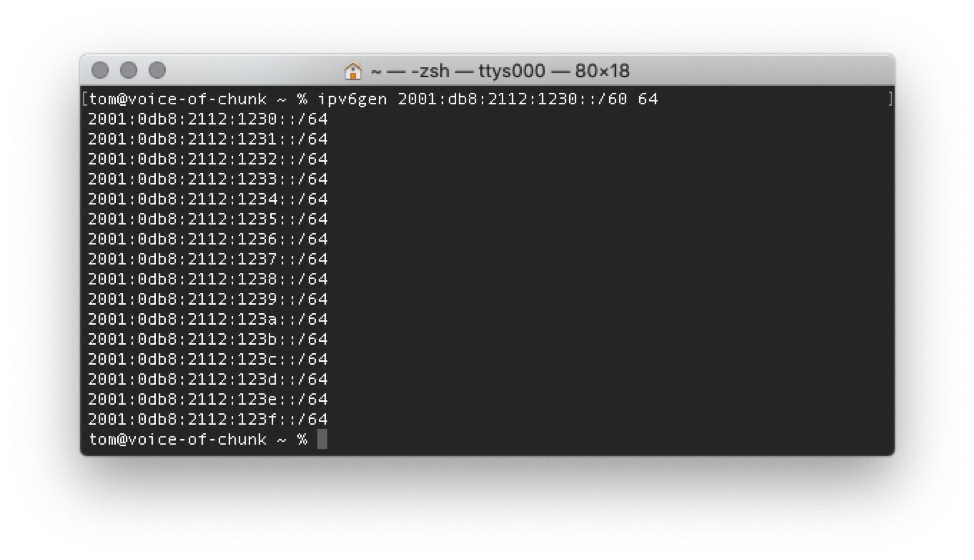 Next available allocation typically works by assigning the next available prefix from the list of all prefixes. In the above example, the /64s would most likely be assigned to network interfaces. Using the next available allocation method, a network interface needing an IPv6 prefix would get the next available prefix in the list. For example:
Next available allocation typically works by assigning the next available prefix from the list of all prefixes. In the above example, the /64s would most likely be assigned to network interfaces. Using the next available allocation method, a network interface needing an IPv6 prefix would get the next available prefix in the list. For example:
2001:db8:2112:1230::/60 2001:db8:2112:1230::/64 -> Reserved 2001:db8:2112:1231::/64 -> VLAN 1 2001:db8:2112:1232::/64 -> VLAN 343 2001:db8:2112:1233::/64 -> VLAN 400 ... 2001:db8:2112:123f::/64 -> Reserved
You may have noticed from the example above; this method doesn’t presume any particular order or organization of the elements needing a prefix assignment. It simply dictates that whatever element needs a prefix of a particular size (in this case, a /64) from a particular larger allocation (in this case, a /60) gets the next available prefix from the list of available prefixes.
Note that if I were actually numbering VLANs, I might wish to use a scheme that aligns the VLAN number to the prefix being assigned. If my network configuration uses extended VLANs at least 4094 unique /64 prefixes I would be need to map them all to specific VLANs. This would require at least a /52, which in turn would provide 4096 /64s.
2001:db8:2112:1000::/52 2001:db8:2112:1000::/64 - Reserved 2001:db8:2112:1001::/64 - VLAN 0001 (Don't use VLAN 1! ;)) 2001:db8:2112:1002::/64 - VLAN 0002 2001:db8:2112:1003::/64 - VLAN 0003 ... 2001:db8:2112:100a::/64 - VLAN 0010 ... 2001:db8:2112:1920::/64 - VLAN 2336 ... 2001:db8:2112:1ffe::/64 - VLAN 4094
Obviously, with this method it helps if you can easily convert hexadecimal to decimal, something which may pose challenges to your operations teams. Alternatively, by using a /48, no hexadecimal to decimal conversion would be necessary. For example:
2001:db8:2112::/48 2001:db8:2112:0000::/64 - Reserved 2001:db8:2112:0001::/64 - VLAN 0001 (Don't use VLAN 1! ;)) 2001:db8:2112:0002::/64 - VLAN 0002 2001:db8:2112:0003::/64 - VLAN 0003 ... 2001:db8:2112:0010::/64 - VLAN 0010 ... 2001:db8:2112:2336::/64 - VLAN 2336 ... 2001:db8:2112:4094::/64 - VLAN 4094
A caveat with this approach is that one is consuming only 6% of the /48 for that particular application. Of course, we could use the remaining prefixes in an ad-hoc fashion (especially where IPAM can help keep track of them). Even if we don’t assign any prefixes beyond the 6% for extended VLANs, there is no requirement to avoid this method to conserve IPv6 address space.
For this example, I picked on one of the smallest prefixes allowing for subsequent, more granular subnet assignments (i.e., /60 -> /64), but of course this method works just as well with larger prefix allocations. For example, a RIR might assign a /44 to a small enterprise with 12 or fewer sites.
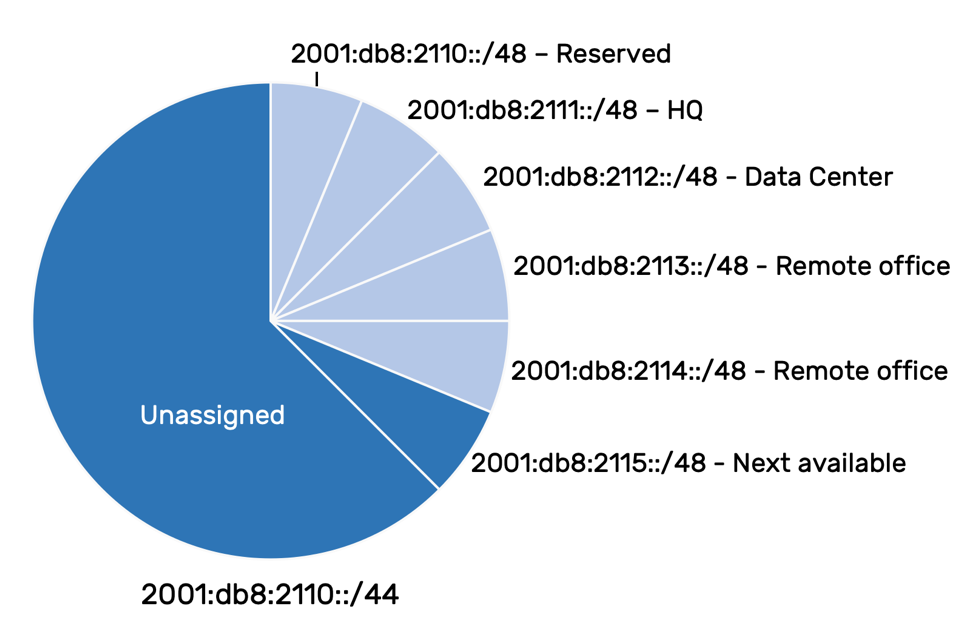
2001:db8:2110::/44 2001:db8:2110::/48 – Reserved 2001:db8:2111::/48 – Site 1 - HQ 2001:db8:2112::/48 – Site 2 - Toronto Data center 2001:db8:2113::/48 – Site 3 - Remote office 2001:db8:2114::/48 - Site 4 - Remote office 2001:db8:2115::/48 – Next available ... 2001:db8:211f::/48 – Reserved
Another way to visualize this and other allocation methods is by using a pie chart:
Reserving Zero Prefixes
Incidentally, you probably noticed that in the above allocation examples, I didn’t use the first available prefix for an actual assignment but instead marked it as reserved. There are two beneficial reasons for this. The first is that it avoids potential confusion between two prefixes that share the exact same label but differ in size. For example, in standard zero compressed format:
2001:db8:2110::/44 2001:db8:2110::/48
Without referencing the CIDR notation, I can’t immediately determine whether I’m looking at the entire block (i.e., 2001:db8:2110::/44) or merely the second available prefix from it (i.e., 2001:db8:2110::/48). We network engineering types naturally pride ourselves on our precision and accuracy. But we’ve also likely got the operational battle scars from middle-of-the-night outages. Those outages where, in spite of our best precision-and-accuracy intentions, we misread one prefix for another. By not using the first subnet from each larger block, we can entirely avoid any such confusion.
The second beneficial reason to reserve the first available prefix is a bit more direct. When labeling things, it’s convention to start enumerating them from “1”. By not using the first available prefix from the larger allocation (which will always end in “0”), we’ll always start assigning prefixes beginning with “1”.
That’s it for part one! Next time we’ll cover the remaining IPv6 prefix allocation methods sparse, best fit, and random.
Thanks for reading!
Tom Coffeen (@ipv6tom) is a co-founder of HexaBuild, an IPv6 consulting and IPv6 training company. Tom is the author of IPv6 Address Planning on O’Reilly Media. You can follow HexaBuild on Twitter and LinkedIn.






