




In part 4 of Turbocharge your Infoblox RESTful API calls series, we discuss what asynchronous programming is, and how it can be implemented to dramatically improve the speed of automation scripts.
OVERVIEW
In this fourth and final article of the Turbocharge your Infoblox RESTful API calls series, we explain what async programming is, its pros and cons, as well as demonstrate how how it can be leveraged to vastly improve the performance of scripts which make use of the Infoblox WAPI. In this article we will again take our original WAPI script which inserts 1,024 IPv4 network objects into the grid, and refactor it into a script which leverages async programming. For this, we will use the aiohttp and asyncio Python libraries to make async calls to the WAPI.
NOTE: If you are a regular user of the infoblox-client Python client wrapper to the WAPI, you will not be able to leverage async calls since it is not supported by the software. There is an open request to have that added, but at the time this article was written, no support for async had been added.
The code used in development of this article series is accessible at https://github.com/ddiguru/turbocharge_infoblox_api
Async Programming
Asynchronous programming is the opposite of synchronous programming. A synchronous program has a one-track mind. The flow of a synchronous script is step-wise. It performs each step (task, method or function) one at a time and completes it before moving on to the next step or chunk of data. In the last article, we used batch processing by stuffing numerous network objects into a single request WAPI call, this too is an example of a synchronous script.
An async program or script behaves differently. It still uses a single thread of execution at a time, but the difference is that the system does not have to necessarily wait for the step (task, method, or function) to be completed before moving on to the next one. An async script can effectively launch several tasks in succession without having to wait for responses before starting others. The program knows what to do when a previously launched task does finish running.
Pros
- async programs are typically written to be non-blocking
- super fast!
Cons
- more complex to write
- requires specific async versions of libraries, i.e. it is not supported in infoblox-client
- poorly written tasks can block, delay or starve outstanding tasks that need running
Since we’re loading 1,024 networks, we want to do so as quickly as possible. Our business logic is simple and very well suited for async programming, because we effectively want to “shove it in there”. Our script doesn’t have any dependencies that have to be solved between each network. It’s truly “best effort” – try to get them all inserted/created and maybe output to a log any that fail.
Recall the original synchronous script logic for adding networks was as follows:
# create IPv4 Network object(s) one at a time
for network in networks:
payload = dict(network=str(network), comment='test-network')
s.post(f'{url}/network', data=json.dumps(payload), verify=False)We refactored the above script to use asynchronous logic for adding networks as follows:
auth = aiohttp.BasicAuth(login=ibx_username, password=ibx_password)
async with aiohttp.ClientSession(cookie_jar=aiohttp.CookieJar(unsafe=True)) as session:
async with session.get(f'{url}/grid', auth=auth, ssl=False) as res:
logger.debug(res.status)
tasks = []
sem = asyncio.Semaphore(16)
for network in networks:
task = asyncio.ensure_future(load_network(sem, session, network))
tasks.append(task)
responses = asyncio.gather(*tasks)
await responsesNote: the call to load_network(sem, session, network) – we implement that quite simply with a simple function the following:
async def load_network(sem, session, network):
async with sem:
await fetch(session, network)The load_network method call takes a semaphore, our session, and a network object as args and asynchronously calls another method called fetch. This is the non-blocking method will make the async call to the server.
async def fetch(session, network):
payload = dict(network=str(network), comment='test-network')
async with session.post(f'{url}/network', data=payload, ssl=False) as res:
if res.status == 201:
logger.info(f'successfully inserted network {str(network)}')
else:
logger.error(f'failed to load network {str(network)}')The difference is that it’s an async function call. The function is called without waiting for the response. See the full listing for wapi-async.py
If we graphically depict the flow and operation of our refactored async script for creating network objects, it would look something like the following:
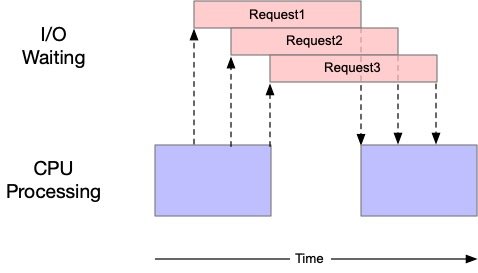
Each numbered request is an async task which creates or inserts one IPv4 Network at a time. This is yet another script which makes use of concurrency – the difference is, the script is actually single threaded. Asynchronous programs use cooperative multitasking instead of preemptive multitasking. The operating system does not do any context switching, instead, tasks voluntarily yield control periodically – at completion, when they are idle, or logically blocked. It’s said to be cooperative because all programs must cooperate in order for the scheduling scheme to work. In the example above, we use a Semaphore as a mechanism to control the max number of tasks that can run at any given time. This is analogous how we limited the max number of threads in our ThreadPool in the second article.
Results
When I started to test wapi-async.py against wapi-network.py, I noticed performance of the script varied widely as I tuned the script for how many semaphores to use. Therefore, the script was tested numerous times with different semaphore values, starting with 2 and ending with 32 semaphores. Notice how the performance drops off significantly when we use a value of 32!
| Test | Pass #1 | Pass #2 | Pass #3 |
|---|---|---|---|
| wapi-network.py | 33.85 | 33.64 | 33.33 |
| wapi-async.py w/ 2 semaphores | 23.56 | 23.40 | 23.64 |
| wapi-async.py w/ 4 semaphores | 23.99 | 19.99 | 21.56 |
| wapi-async.py w/ 8 semaphores | 19.26 | 19.39 | 19.50 |
| wapi-async.py w/ 16 semaphores | 27.81 | 23.13 | 23.87 |
| wapi-async.py w/ 32 semaphores | 55.31 | 55.50 | 55.80 |
| % improvement | 43.10% | 42.36% | 41.50% |
The sweetspot seems to be 8 semaphores – results may vary according to how busy the Grid Master is. Recall, this testing is done in an isolated lab with minimal load on the Grid Master. So, the sweetspot may be lower in a production environment. The performance improvement shown above is a result of comparing our base script with the async script using the sweetspot of 8.
NOTE: this test was performed with HTTP Keepalive enabled.
Overall, the async script was more than 40% faster in loading the 1,024 networks into the Grid.
Conclusion
A lot of different programming techniques were discussed in this series of articles to help increase the performance of your automation scripts. Here are the main takeaways:
- Enable HTTP Keepalive on your Infoblox Grid – There’s no reason not to!
- Experiment with Python threading, and Python asyncio modules. See where they fit in your helping you develop your trove of scripts for improving your automation.
- Implement the Infoblox WAPI request module in your scripts when you are performing predictable data insert operations to load networks, zones, DNS resource records, etc.
- Experiment and Test (wash, rinse, repeat)
While none of these things are going to be a panacea in all situations, there is going to be a time and opportunity for each. If you learn, experiment, and test thoroughly with these techniques to bolster your skill set, you will NOT be disappointed and they will serve you well!


