
Let me begin this blog by starting with an analog to one of those detective TV shows we have all watched: A terrible crime occurs, a weapon is found, with fingerprints that conveniently match a suspect that the police already have in custody. It’s an open and shut case. Right? Well, not necessarily–and it makes for a great bit of drama.
Just like the recently publicized Facebook outage, DNS was initially the prime suspect, too. An open and shut case? Well, again, not necessarily. In a plot twist to the story, despite initial perceptions that Facebook suffered a massive DNS outage, it was instead an erroneous network configuration with far-reaching impacts. Not only was Facebook affected–network operators worldwide were forced to adjust their DNS infrastructure so they would not be taken down as well.
Let’s talk about You and Me; Let’s talk about BGP
(Then let’s talk about DNS).
Border Gateway Protocol (BGP) is the routing protocol that more or less connects the entire Internet. Routing in most local area networks is reasonably straightforward. Every device is more or less connected to the same “managed” computer network. Through the use of local network addresses such as RFC 1918 in the case of IPv4, or using various suggested methods of IPv6, if “node A” wants to connect with “node B” on the same infrastructure, it can usually do so relatively directly, and ideally without translation. Easy-peasy right? Isn’t that nice?
Beyond smaller LANs and non-exposed hosted services, BGP is how larger Internet peers, peering systems (interconnecting “routers”) tell each other how to communicate and what “routes” are available to go from one network or subnet to another. Large organizations and most ISPs manage internet connectivity for multiple network sites and locations, each known as an autonomous system (AS) and often employ change controls using solutions like Infoblox’s own Network Automation and Policy product called NetMRI to review and approve mass network change.
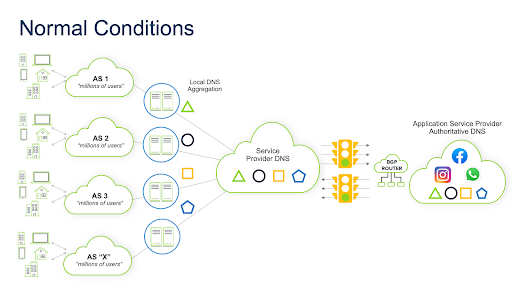
While networks may choose BGP “i” nside a private AS handle routing for their local traffic, an “e” xternal router directs all inbound traffic from other “external” AS’s into the locally known autonomous system. All outbound traffic goes to the Internet from inside the AS. The public Internet comprises thousands of these autonomous systems, and BGP dynamically directs how packets should be forwarded between them. Of particular note, when a BGP router connects to a router in a neighboring external AS, it’s called external BGP, or “eBGP.” Each eBGP router contains routing tables it can use to find peers and paths on the global Internet using authentication and a mutually established timer mechanism. When a BGP router receives a packet forwarding request, it uses the state of this information to determine the “best” available path to the destination. For BGP to work, AS operators use these settings to establish trust with each other. They configure peering agreements that enable them to establish direct connections with each other and permit BGP traffic to travel throughout their autonomous systems. They also occasionally implement very low timers (typically under 1 second) to intentionally “fail” relationships leveraging a well-known protocol known as “Bidirectional Forwarding Detection” or BFD for short to hasten the action/reaction of peering changes. Here’s a simple diagram showing how things worked before the outage:
So, what happened?
Facebook (or any other provider or organization who wishes) maintains their own AS. This infers that they also define the routes to inform other networks to talk to their subnets. On the day of the outage, someone or something inadvertently removed all routes to speak to some very important subnets (where the central DNS servers for multiple services/applications used to live).
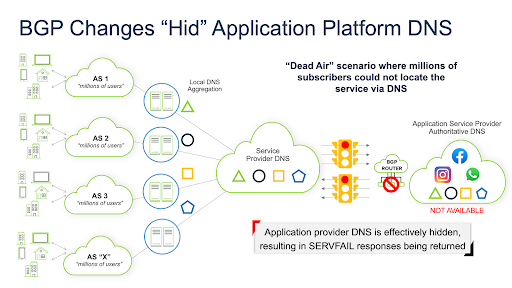
It’s like pulling your name and phone number from the phonebook and privately listing yourself. If people directly call your number (static routes), they’ll still find you. But you’re not listed in the phonebook anymore. How am I supposed to locate you in the first place? It’s a nasty catch 22 that created a lot of interesting downstream effects. And it takes time after you realize you’ve had this error for things to be “republished” and, in turn, the rest of the Internet to figure out where you are again. Since all routes to communicate with their DNS servers from the outside world were effectively deleted. It is impossible to manage static routing/peering at this scale. Millions and Millions of subscribers and IoT devices could not resolve the IPv4 or IPv6 addresses of the Facebook services or domain names.
What Was The Result?
As these services and domain names reference multiple products and platforms, the issue was compounded. Instead of talking about the past (the error that occurred on the network), lets focus on what we observed afterward. Essentially what we all experienced in this error affected the DNS and, therefore, parts of the Internet at large. The sheer number of subscribers of the Facebook network played an unsurprising but critical role. There’s a tremendous number of mobile devices, big computers and tiny computers, interesting little IoT devices, and all sorts of IP-enabled software all over the Internet that talks to Facebook’s various services regularly all day long. And it turns out when you take away what they want to talk to, there are far-reaching effects that weren’t expected or adequately planned for. The Internet became extremely busy when Facebook “quietly” went off the air. You’ve got all these queries coming from devices–mobile handsets, etc., and those devices all do at least one lookup, and they’re all pinging away trying to find facebook.com, finding only dead air. Dead air in the world of DNS is a terrible thing. You want a response. Whether that response is positive or negative, redirection or otherwise, you want a response–and when there’s no response, repeatedly, these queries can take a while to “time out”. They can, and do stack up on top of one another, and hence the problem can have a so-called “snowball effect.”
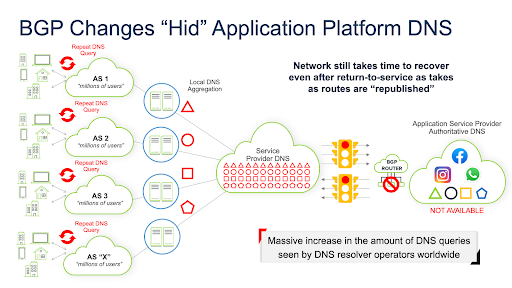
Unlike large enterprise networks, the networks that routinely saw the most significant impact from this “dead air effect” were top-Tier global network operators because they act as giant network traffic aggregators for B2C and B2B services, including much of the “last-mile” DNS traffic. network operators frequently do not see the actual client device; instead, they only see the apex of that enterprise’s NAT/FW or dedicated local DNS infrastructure as a resolver. These networks typically have far more subscribers and devices talking to their centralized DNS services than most companies do. While home subscribers may have 10’s to 100’s of devices behind their gateway, imagine a large company with armies of users and devices transmitting DNS queries through just a few local forwarders or Active Directory DNS servers. Factor in that most devices now speak IPV4 and IPV6. We are essentially doubling (or more with split VPN/SD-WAN type implementations and IPv6’s fancy privacy functions) this traffic flow throughout the entirety of global DNS environments. And that is another force multiplier for this problem. With just one company knocking on a Telcos DNS front door, its 100,000 users behind it, potentially from one IP address, it can create widespread havoc, even with the widespread belief that BCP-38 and valuable packet filtering devices are in place. On day zero of these unexpected outages, operators may have found themselves scrambling for the same old “bolt-on” networking solutions like application delivery controllers (load balancers) or firewalls to try their best to save their services where a “built-in” tuning session with Infoblox’s in-line DNS products would resolve some or most service issues related to this type of event. Let’s examine several key ways available Infoblox solutions can be employed and correctly tuned to maximize availability and the lowest latency subscriber experience.
How Can Infoblox Help Network Operators?
While numerous best practices exist that help enterprises and network operators ensure that networks and services are online, human error is still a fact–and this outage is an excellent example of that. Humans run the network, and humans run or train the machine learning AI running the network. Luckily, Infoblox can help network operators protect themselves from situations like this in several ways.
Advanced DNS Protection (ADP)
Whether you’re under attack or just regularly processing traffic, as a DNS server from Infoblox, Advanced DNS Protection (ADP) is your shield between your DNS server itself and the intentional or unintentional DNS attack. From the perspective of this outage, consider what happens when things come back online–there is a tsunami of requests to this critical shared service as networks turn back on and begin connecting. They’ve been buffering a lot of traffic, waiting for the moment where they can reach each other again, and there is no flow control. ADP allows network operators to rate limit good and bad traffic and temper that attack. And whether it’s an unintentional attack or not, it’s effectively a line rate attack on the DNS service.
Fault-tolerant DNS Cache Acceleration (DCA)
Infoblox offers the most robust and cost-effective DNS caching infrastructure solutions. Besides sub-millisecond response and advanced threat protection, Infoblox DNS Cache Acceleration (DCA) also provides fault-tolerant caching. DCA allows for a fault on the other end to be tolerated. In this “dead air” scenario, NIOS can automatically be orchestrated via standard API or operators to request the DNS server to “freeze” the cached last known good entries instead of stacking up more DNS queries that can’t be served.
Advanced Reporting & Analytics
I mentioned the benefits of ADP earlier. While it’s one thing to stop this traffic, it’s another to intelligently understand the flow rate and where these queries are coming from to tune DNS settings. network operators need to know what type of traffic it is, what query type it is, and what’s being hit to effectively create the tuning environment that we’re talking about here. Reporting is a valuable part of the Infoblox grid solution that provides you with that critical detail. To correctly tune right, it’s this full circle of understanding, and you need the ability to see the problem. And then, you need to formulate the fix for the problem and then implement it. And so the formulation and the implementation of that is ADP “sees” the problem. Knowing how to create that tuning environment is the reporting piece. While these components are potent in and of themselves, they are force multipliers when used together. See the following community posts for some excellent example dashboards:
Holddown, Fetches per Zone, Fetches per Server (NIOS)
Infoblox’s Network Identity Operating System (NIOS) is the operating system that powers our distributed core network services suite known as “the Grid.” Ensuring the non-stop operation of network infrastructure, the DNS protocol engine in NIOS has built-in critical features designed to help but may require tuning to be most effective.
Network operators traditionally are advised to tune for different DNS traffic flow expectations due to the need to adjust for their massive and often “surging” traffic profiles. Holddown and fetches per server, for example, refers to the time that goes by (time as a variable between queries and how that gets calculated) to allow the opening of the next socket for another DNS resolver or server procedure to connect during its recursing actions. These tuning options are highly effective at helping better inform and better prepare network operator DNS engines for these “dead air” scenarios and are best used in conjunction with well-tuned Advanced DNS Protection for maximum availability and uptime of services.
Trinzic FLEX and Service Provider Licensing = Flexibility to absorb the Unknown
We’ve often heard DNS and routing referred to as the “plumbing of the internet,” so to use an apropos analogy, while you’re figuring out the problem under that leaky faucet, it sometimes helps to have a bucket available, but what about when that bucket gets full? Scalable environments act as “sponges” for these types of outages and attacks. Infoblox Trinzic Flex virtual appliances, combined with our Service Provider License Agreement Program (SPLA), enable carriers to meet unanticipated demands that may not be accurately predicted. Combined, the solution provides much-needed elasticity and visibility in situations like this event, allowing providers and operators to increase capacity via orchestration without pausing to procure new licenses for software or hardware-based approaches. Additionally, consider the giant tsunami of DNS requests mentioned earlier. Infoblox doesn’t penalize providers having to deal with all of those DNS requests as we will only charge for those queries successfully processed and not the ones that get filtered or dropped by necessity.
Infoblox Helps You Prepare
Experienced practitioners, well-prepared architecture, accurate telemetry systems, and trained, savvy operators are all essential and all-too-often overlooked pieces of the five nines uptime game. Just like a crime story, initial reports of this recent outage zeroed in on DNS as the culprit, but as Infoblox’s very own Cricket Liu noted, it’s easy to conflate DNS issues with BGP ones. DNS servers may appear to be down, but that could result from BGP routes blocking access to specific DNS servers. Facebook’s engineering team wrote a great explanation of the event which is also well worth a read.
Fortunately, network operators can leverage Infoblox capabilities and expertise to prepare for these unknowns, whether the intent was malicious or not. Best practices from industry sages such as Cricket and all of our highly trained and experienced industry experts are freely published and kept up to date right here on our community portal: https://community.infoblox.com/t5/Best-Practices/bg-p/best_practices, and we do hope to see you online and asking questions! Avoid falling for so-called “ambulance chasing” generic messaging like “Our all that and a bag of chips solution would have fixed that, and everything else too.” Don’t become host to the next “network crime” (outage) or become a victim of one as an “innocent bystander” with an unprotected, best effort basic DNS solution. Contact your Infoblox team today to learn more about how we can help.